pivot-lang immix gc
本文档将会描述pl使用的immix gc的一些实现细节与对外接口
Table of Contents
Overview
此gc是我们基于immix GC论文实现的, 大部分的实现细节都与论文一致,对于一些论文没提到的细节我们自行进行了实现,参考了很多别的GC项目。该GC是一个支持多线程使用的、 基于StackMap的,半精确mark-region 非并发(Concurrency) 并行(Parallelism) gc。
gc中并发和并行是两个不同的术语,并发gc指的是能够在应用不暂停的基础上进行回收的gc, 而并行gc指的是gc在回收的时候能够使用多个线程同时进行工作。一个gc可以既是并行的也是并发的, 我们的immix gc目前只具备并行能力
这里有一些创建该gc过程中我们主要参考的资料,列表如下:
- immix gc论文
- playxe 的 immixcons(immix gc的一个rust实现,回收存在bug)-- 很多底层内存相关代码是参考该gc完成的,还有在函数头中加入自定义遍历函数的做法
- 给scala-native使用的一个immix gc的C实现
- 康奈尔大学CS6120课程关于immix gc的博客,可以帮助快速理解论文的基本思路
General Description
本gc是为pl 定制的,虽然理论上能被其他项目使用,但是对外部项目的支持 并不是主要目标
pl的组件包含一个全局的GlobalAllocator,然后每个mutator线程会包含一个独属于该线程的Collector,每个Collector中包含一个
ThreadLocalAllocator。在线程使用gc相关功能的时候,该线程对应的Collector会自动被创建,直到线程结束或者
用户手动调用销毁api。
mutator
mutator指使用gc的用户程序,在有些文档里也被指代为gc的client
block
block是immix中全局分配器分配的基础单位,每个block的大小为32KB
line
line是block中的基本单位,每个line长度为128B,每个block中包含256个line
Global Allocator
全局分配器,简称GA,分配内存以block为单位
Thread Local Allocator
线程本地分配器,简称TLA,分配内存以line为单位,在自身的block中分配,如果没有可用的block,会向全局分配器申请
Collector
线程本地的回收器,在每次gc开始的时候会运行标记和驱逐算法,然后通知Thread Local Allocator进行清扫
Evacuation
驱逐算法,是一种反碎片化机制
下方是使用immix gc的应用程序的工作流程图:
graph LR;
subgraph Program
style Collector1 fill:#b4b2e6
style Collector2 fill:#b4b2e6
direction TB
subgraph Immix GC
direction TB
GA
Collector1
Collector2
end
GA[Global Allocator]--give blocks-->TLA1;
TLA1-.return free blocks.->GA;
subgraph Collector1
direction TB
TLA1[Thread Local Alloctor]
Marker1[Marker]
end
GA--give blocks-->TLA2;
TLA2-.return free blocks.->GA;
subgraph Collector2
direction TB
TLA2[Thread Local Alloctor]
Marker2[Marker]
end
subgraph Mutator
direction TB
Thread1
Thread2
end
TLA1--lines-->Thread1
TLA2--lines-->Thread2
Marker1-.Mark, evacuate.->TLA1
Marker2-.Mark, evacuate.->TLA2
end
Immix GC由于分配以line为单位,在内存利用率上稍有不足,但是其算法保证了极其优秀的内存局部性,配合TLA、GA的设计也大大 减少了线程间的竞争。
Allocation
Global Allocator
GA是全局的,一个应用程序中只会有一个,负责分配block。在GA被初始化的时候,会向操作系统申请一大
块连续的内存,然后将其切分为block,每个block的大小为32KB。GA有一个current指针,指向
目前GA分配到的位置。当GA需要分配新block的时候,GA会返回当前current指针指向的内存空间,
并且将current指针向后移动一个block的距离。
GA同时维护一个free动态数组,用于存储已经被回收的block,当GA需要分配新block的时候,会先从free数组中
尝试取出一个block,如果free数组为空,才会分配新的block。
Thread Local Allocator
TLA是线程本地的,每个线程都会有一个TLA,负责分配line,和进行sweep回收。
- 小对象:小于line size的对象
- 中对象:大于line size,小于block size/4(8KB)的对象
- 大对象:大于block size/4的对象
- hole:block中一个未被使用的连续空间称之为hole
在每次回收的时候,TLA会将所有完全空闲的block回收给GA,所有部分空闲的block会被加入到recycle数组中,在之后的分配里被重复利用。
所有完全被占用的block会被加入到unavailable数组中,不会被重复利用。
TLA的小对象分配策略如下:
graph TD;
A[分配内存]-->B{有recycle block?}
B--是-->C[从recycle block中分配line]
B--否-->D{申请新block}
D--成功-->E[新block加入recycle block]
D--失败-->I[panic]
E-->C
C-->F{block用完?}
F--是-->G[移入unavailable block]
F--否-->H[返回分配空间的指针]
G-->H
中对象存在一个问题,就是如果他采用小对象的分配策略,在recycle block中分配line,那么分配过程中可能跳过 很多的小hole,而TLA的分配器在recycle block中分配的时候是不回头的,这样可能会导致:
- 内存碎片增加
- 分配时间变长
因此,中对象分配的时候只会找recycle block中的第一个hole,如果这个hole装不下它,TLA会直接申请新的block来分配该对象, 并且将这个block加入到recycle block中。
大对象分配不使用mark region算法,它使用特殊的bigobject allocator来分配,是传统的mark free算法。
因为程序中小对象的数量远远大于中对象和大对象,所以TLA的分配器会优先优化小对象分配,以增加性能
Mark
Mark阶段的主要工作是标记所有被使用的line和block,以便在后续的sweep阶段进行回收。我们的mark算法是__精确__的, 这点对evacuation算法的实现至关重要。
精确GC有两个要求:
- root的精确定位
- 对象的精确遍历
我们的精确root定位是基于__Stack Map__的,这部分细节过于复杂,将在单独的文档中介绍。
对象的精确遍历是通过编译器支持实现的,plimmix将所有heap对象分类为以下4种:
- Atomic Object:原子对象,不包含指针的对象,如整数、浮点数、字符串等
- Pointer Object:指针对象,该对象本身是一个指针
- Complex Object:复杂对象,该对象可能包含指针
- Trait Object:Trait对象,该对象包含一个指针,在他的offset为8的位置,这个类型是专门配合pivot lang的trait设计的,是个特殊优化
对于Atomic Object,我们不需要遍历,因为他们不包含指针。
对于Pointer Object,我们只需要遍历他们的指针即可。
对于Complex Object,编译器需要在对象开始位置增加一个vtable字段,该字段的值指向该类型的遍历函数。此遍历函数由编译器生成,
其签名为:
pub type VisitFunc = unsafe fn(&Collector, *mut u8);
// vtable的签名,第一个函数是mark_ptr,第二个函数是mark_complex,第三个函数是mark_trait
pub type VtableFunc = fn(*mut u8, &Collector, VisitFunc, VisitFunc, VisitFunc);在标记的时候,我们会调用对象的vtable对他进行遍历
对于Trait Object,我们需要遍历他指向实际值的指针
下方是一个immix heap的示意图,其中*表示该对象会在mark阶段中被标记
graph LR;
subgraph Stack
Root1
Root2
Root3
Root4
end
subgraph HO[Heap]
AtomicObject1[AtomicObject1*]
AtomicObject2[AtomicObject2*]
AtomicObject3
PointerObject1[PointerObject1*]
PointerObject2[PointerObject2*]
ComplexObject1
end
subgraph ComplexObject1[ComplexObject1*]
VT1[VTable]
PF1[PointerField]
AF1[AtomicField]
ComplexField
end
subgraph ComplexField
VT2[VTable]
AF2[AtomicField]
PF2[PointerField]
end
PF1 --> PointerObject1
PF2 --> AtomicObject2
PointerObject1 --> AtomicObject1
PointerObject2 --> ComplexObject1
Root1 --> PointerObject1
Root2 --> PointerObject2
Root3 --> PointerObject1
对于ComplexObject1,他的vtable函数逻辑如下:
fn vtable_complex_obj1(&self, mark_ptr: VisitFunc, mark_complex: VisitFunc, mark_trait: VisitFunc){
mark_ptr(self.PointerField)
mark_complex(self.ComplexField)
}而对于ComplexField,他的vtable函数逻辑如下:
fn vtable_complex_field(&self, mark_ptr: VisitFunc, mark_complex: VisitFunc, mark_trait: VisitFunc){
mark_ptr(self.PointerField)
}实际上,mark_complex和mark_trait逻辑都十分简单:mark_complex只是调用对象的vtable函数,而
mark_trait只是对实际指针调用mark_ptr,真正的标记和驱逐逻辑都在mark_ptr中实现。
标记过程开始的时候,gc会load所有root指向的值,对他们调用mark_ptr,如果该值为gc堆中的对象,
则会将该对象标记,并且再次load它指向的对象,若该对象非AtomicObject类型则加入到mark queue中。
在mark queue中的对象,会被逐个取出,根据他们的类型对他们调用mark_ptr、mark_complex或者mark_trait,直到
mark queue为空,则标记过程结束。
尽管这的确可以看作是一个递归的过程,但是此过程一定不能使用递归的方式实现,因为递归的方式在复杂程序中可能会导致栈溢出。
Sweep
Sweep阶段的主要工作是:
- 回收所有未被标记的block
- 修正所有line的header
- 计算evacuation需要的一些信息
回收block
回收block的过程非常简单,我们只需要遍历所有的block,如果block的header中的mark字段为false,则将该block回收,统一返回给GA
修正line header
如果一个block被mark了,那么需要对block中的所有lineheader根据line是否被标记 进行修正。
计算evacuation信息
计算一个mark数组,该数组中下标为idx的元素值表示hole数量为idx的所有block的marked line的数量
Evacuation
每次回收开始之前,我们会先判断是否需要进行反碎片化,目前的策略是只要recycle block>1就进行反碎片化。
如果决定了需要进行反碎片化,那么我们会构建一个available数组,该数组中下标为idx的元素值表示hole数量为idx的所有block的可用line的数量,
然后我们按照洞的数量从大到小遍历available和mark数组,会定义一个required值,该值在每次遍历的时候加上mark数组中的值,
减去available数组中的值,如果某次循环后required值小于0,那么当前循环对应的hole数量+1就是我们evacuate的阈值(threshold)。
在此之后根据threshole将所有洞数量大于等于threshole的block标记为待evacuate。
真正的evacuation过程是在mark阶段一起完成的,我们会在遍历到处于待evacuate的block中的对象时,为它分配一个新的地址,并且
将它原地址的值替换为一个指向新地址的指针(forward pointer),且将line header中的forward字段设置为true。之后如果再次遍历到
该对象,收集器会修正指向原地址的指针的值,这一过程我们称之为自愈。该过程如下图所示
graph TD;
subgraph BeforeEva
direction TB
EvaBlock
EmptyBlock
Pointer
end
subgraph EvaBlock
Line1
Line2
LineK[...]
LineN
end
subgraph Line1
Addr[addr: 0x1000]
Value[value: 0x4321]
Forward[forward: false]
end
subgraph EmptyBlock
EL1
ELK[...]
end
subgraph EL1[Line1]
AddrEL[addr: 0x2000]
ValueEL[value: 0x0000]
end
Pointer
Pointer-->Line1
subgraph AfterEva
direction TB
EvaBlock1
EmptyBlock1
Pointer1[Pointer]
end
subgraph EvaBlock1[EvaBlock]
Line11
Line21[Line2]
LineK1[...]
LineN1[LineN]
end
subgraph Line11[Line1]
Addr1[addr: 0x1000]
Value1[value: 0x2000]
Forward1[forward: true]
end
subgraph EmptyBlock1[EmptyBlock]
EL11
ELK1[...]
end
subgraph EL11[Line1]
AddrEL1[addr: 0x2000]
ValueEL1[value: 0x4321]
end
Pointer1-->EL11
BeforeEva-->AfterEva
每次驱逐是以分配的对象为单位,如果一个block被标记为待evacuate,那么在驱逐过程中,该block中的所有对象都一定会被驱逐。
请注意,一部分其他gc的驱逐算法中的自愈需要读写屏障的参与,immix不需要。这带来了较大的mutator性能提升。
驱逐算法的正确性建立在我们的root定位和对象遍历的正确性之上,如果root定位和对象遍历不精确, 建议禁用驱逐算法。这二者的不精确会导致驱逐算法修改的指针不能完全自愈。考虑下方场景:
struct Node {
next: *mut Node,
data: u32,
}
fn main() {
let mut root = Node {
next: null_mut(),
data: 0,
};
let stack_ptr = &mut root as * mut u8;
add_root(stack_ptr);
}
fn add_sub_ndoe(root: *mut Node) {
let mut node = Node {
next: null_mut(),
data: 0,
};
root.next = &mut node;
}
在这个例子中,我们只添加了一个root即main中的root变量,尽管add_sub_node中的node变量和root参数也是root,
但是不添加它们其实不会影响大部分gc在这个例子中的正确性。然而如果启用了驱逐算法,这个例子就很可能在运行时出错。
假如add_sub_node函数中触发了gc,且gc决定进行驱逐,将main函数中的root变量移动到了新的地址,那么在gc过程中
stackptr对应的指针指向的位置会自愈,更改为移动后的地址,但是add_sub_node函数中的root参数因为没被添加到root set中,
这导致gc无法在回收过程中对其进行修正,就会进一步导致root.next指向的地址不正确,从而导致程序出错。
在多线程情况下,是存在两个线程同时驱逐一个对象的可能的,在这种情况下一些同步操作必不可少,但是并不需要加锁。 我们通过一个cas操作来保证只有一个线程能够成功驱逐该对象。
性能
我们与bdwgc进行了很多比较,数据证明在大多数情况下,我们的分配算法略慢于bdwgc,与malloc速度相当,但是在回收的时候,我们的回收速度要快于bdwgc。 对于一些复杂的测试,在触发回收的策略相同的情况下,我们的单线程总执行时间略慢于bdwgc,但是在多线程情况下,我们的总执行时间明显快于bdwgc, 整体来说机器并行能力越强、测试时使用内存越多immix性能优势越大。
使用github action进行的基准测试结果可以在这里查看,由于github action使用的机器 只有两个核心,所以测试线程数量为2,在此结果中,可以看到immix整体性能略差于bdwgc,但是差距小于单线程情况。
你可以从这里下载测试代码,在你的机器上运行并进行比较。这里我提供一组笔者机器上的测试数据截图
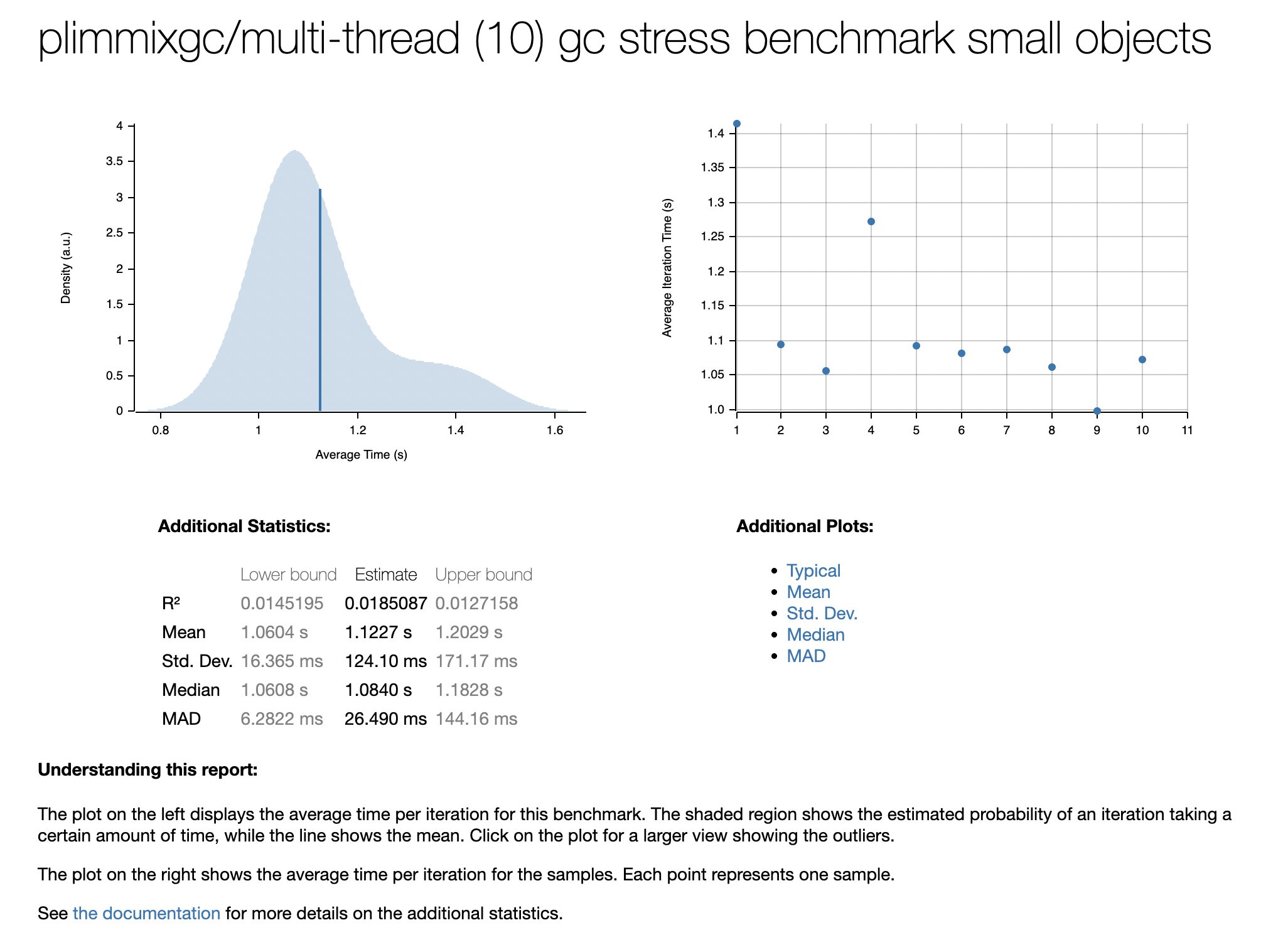
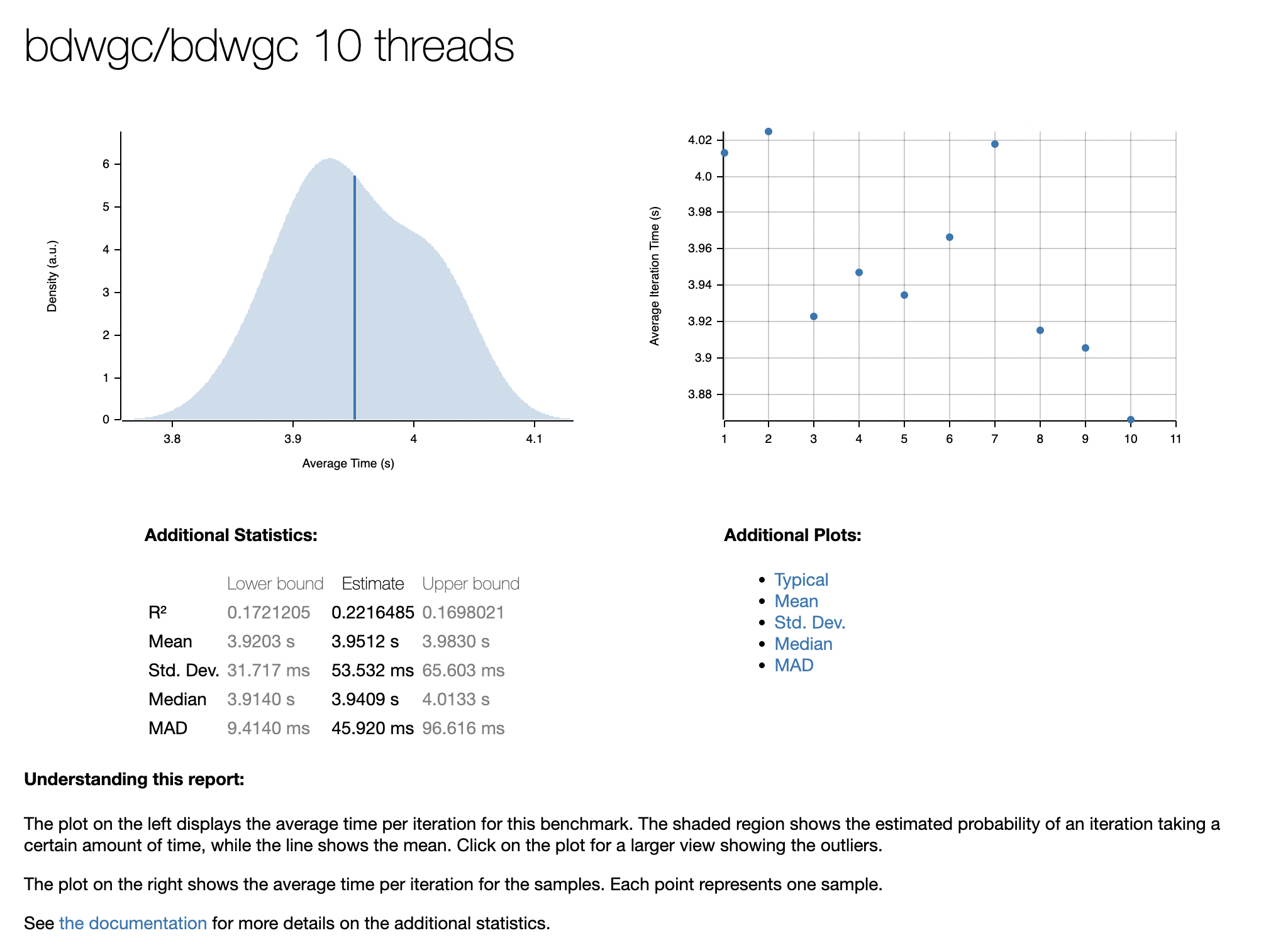
测试环境为MacBook Pro (16-inch, 2021) Apple M1 Pro 16 GB,可以看出immix在此环境中已经具有近4倍的性能优势。
immix作为天生并发的gc,并发情况下几乎能完全避免锁竞争的出现,因此在多线程情况下的性能优势是非常明显的。并且其分配算法很好的维护了空间局部性,理论上 能带来更好的mutator性能。
在线程卡顿的时候
线程进入卡顿状态(Sleep,lock etc.)的时候,需要使用thread_stuck_start通知GC,使GC可以启动一个保姆线程替代卡顿线程的工作。