Pivot Lang
![]()
![]()
![]()

此项目目前处于早期开发阶段,不建议用于生产环境。
项目地址
安装
见此处
官网
CONTRIBUTING
dependencies
重要:如果你想参与开发,请先在项目目录make vm install,然后根据自己是linux还是mac运行make devlinux或者make devmac
特点
- 支持静态编译与JIT
- 高性能
- REPL
- 热重载
- 极其方便的Rust/C互操作
- 支持debug
- 支持lsp,自带vsc插件,能提供优秀的代码支持
- 有GC,自动管理内存
- 强大的类型推断,支持省略大部分类型标注
一些ShowCases
Ray Tracing in One Weekend in Pivot Lang
使用Pivot Lang实现的简单光追

编辑器支持


Hello World
fn main() i64 {
println!("hello world!");
return 0;
}
HashTable
(没错,我们的哈希表源码也是完全用Pivot Lang写的)
use std::cols::hashtable;
use core::panic::assert;
use core::eq::*;
fn main() i64 {
let table = hashtable::new_hash_table(10 as u64, 1 as u64);
table.insert("hello","world");
table.insert("bye","bye");
assert(table.get("hello") is string);
let v = table.get("hello") as string!;
assert("world".eq(&v));
return 0;
}
Fibonacci
use std::io;
fn main() i64 {
let result = fib(10);
println!(result);
return 0;
}
fn fib(n: i64) i64 {
let pre = 0;
let nxt = 0;
let result = 1;
for let i = 0; i < n; i = i + 1 {
result = result + pre;
pre = nxt;
nxt = result;
}
return result;
}
Y组合子
use core::panic;
pub fn main() i64 {
let g = |f, x| => {
if x == 0 {
return 1;
}
return x * f(x - 1);
};
let fact = Y(g);
for let x = 0; x < 10; x = x + 1 {
panic::assert(fact(x) == fact_recursion(x));
}
return 0;
}
struct Func<A|F> {
f: |Func<A|F>, A| => F;
}
impl<A|F> Func<A|F> {
fn call(f: Func<A|F>, x: A) F {
return self.f(f, x);
}
}
fn Y<A|R>(g: ||A| => R, A| => R) |A| => R {
// 下方代码的类型推断是一个很好的例子
return |x| => {
return |f, x| => {
return f.call(f, x);
}(Func{
f: |f, x| => {
return g(|x| => {
return f.call(f, x);
}, x);
}
}, x);
};
}
fn fact_recursion(x: i64) i64 {
if x == 0 {
return 1;
}
return x * fact_recursion(x - 1);
}
Performance
实验证明在经过我们的数次性能优化之后,Pivot Lang的性能已经在很多场景下超越Golang。优化之后的Immix GC在内存分配和回收上的性能也有了很大的提升,能够 在大部分场景下击败别的GC算法。
GC Benchmark
我们使用知名的BdwGC的benchmark代码进行了测试,将Pivot Lang版本与Golang版本以及BdwGC原版进行了对比。
源代码以及结果见:Pivot Lang GC Benchmark
RealLife application performance
我们使用Pivot Lang实现了有名的ray tracing in one weekend项目, 渲染速度相比于golang实现有明显性能优势。
请注意golang的实现代码中的参数与原书不完全一样,测试是在调整成一样的参数之后进行的。
Quick Start: A short introduction to the language
重要:Pivot lang尚属于早期开发阶段,可能会经常发生breaking change,因此不建议在生产环境中使用。
本教程将会从安装出发,简单介绍Pivot lang的语法,以及一些基本的使用规则。
Installation
Windows
windows用户可以使用scoop来安装pivot lang编译器。
请注意,windows环境下的pivot lang编译器目前只支持x64架构,而且依赖MSVC环境。 你需要安装Visual Studio,并在 安装时勾选C++开发环境。
scoop bucket add pivot https://github.com/Pivot-Studio/scoop
scoop install plc
Linux
目前我们对架构为amd64的Ubuntu 20.04 LTS 和 Ubuntu 22.04 LTS提供了apt包。
首先你需要添加我们的apt源的gpg key:
sudo apt update
sudo apt install wget gnupg
wget -O - https://pivotlang.tech/apt/public.key | sudo apt-key add -
然后添加我们的apt源:
sudo touch chmod +777 /etc/apt/sources.list.d/pl.list
sudo chmod +777 /etc/apt/sources.list.d/pl.list
sudo echo "deb [arch=amd64] https://pivotlang.tech/apt/repo focal main
# deb-src [arch=amd64] https://pivotlang.tech/apt/repo focal main
deb [arch=amd64] https://pivotlang.tech/apt/repo jammy main
# deb-src [arch=amd64] https://pivotlang.tech/apt/repo jammy main">/etc/apt/sources.list.d/pl.list
sudo apt update
最后安装pivot lang编译器:
sudo apt install pivot-lang
你可以运行plc来检查是否安装成功。
安装完成后请按照提示设置环境变量
MacOS
MacOS可以使用homebrew进行安装。
首先你需要添加我们的homebrew tap:
brew tap pivot-studio/tap
然后安装pivot lang编译器:
brew install pivot-lang
安装完成后请按照提示设置环境变量
Docker
使用下方命令可以启动一个docker容器,然后在容器中使用pivot lang编译器:
docker run -it --rm registry.cn-hangzhou.aliyuncs.com/pivot_lang/pivot_lang:latest /bin/bash
基础项目
两种编译模型介绍
Pivot Lang存在两种不同的编译方案:
- 静态编译:编译器会将源码编译成一个可执行文件,能给在操作系统上原生运行
- jit编译:编译器会将源码编译成一个字节码文件,然后在运行时使用编译器动态生成可执行代码
目前这两种方案使用的编译器是同一个可执行文件(plc),然而他们在依赖和功能上存在一些差别, 下方是一个简单的对比图:
| jit | 静态编译 | |
|---|---|---|
| 完整的pivot lang功能支持 | ✅ | ✅ |
| 生成可执行文件 | ❌ | ✅ |
| 启动速度 | ❌ | ✅ |
| 运行时优化 | ✅ | ❌ |
| 支持debug | ❌ | ✅ |
| stackmap支持 | ✅ | ✅ |
项目结构
一个最基础的pivot lang项目由一个配置文件和一个源文件组成。
你可以使用plc new test来在test 目录下生成他们。
配置文件用于指定项目的一些基本信息,源文件用于编写pivot lang代码。其结构如下:
test
├── Kagari.toml
└── main.pi
配置文件
一个pl项目的根目录必须有一个名为Kagari.toml的配置文件。示例配置文件的内容如下:
entry = "main.pi"
project = "main"
entry指定了该项目的入口文件,即编译器将从该文件开始编译。如果缺少该配置plc将无法编译该项目
源文件
示例项目中的main.pi为源文件。其内容如下:
use std::io;
pub fn main() i64 {
io::print_s("Hello, world!\n");
return 0;
}
源文件的后缀名必须为.pi。
在示例中,我们调用了一个系统库中的函数print_s,该函数用于打印一个字符串类型的值并换行。此源代码编译后执行会输出Hello World。
编译
如果你已经安装了plc,那么你可以在项目根目录下执行plc main.pi命令来编译该项目。此指令会生成一个名叫out的文件,
还有一些中间文件(在target目录下)。
编译时带上--jit参数,如plc main.pi --jit,这样编译出来的文件会带有bc后缀,如out.bc。
编译后输入plc run out.bc可以jit运行该项目
Visual Studio Code support
我们建议开发者使用Visual Studio Code作为开发工具,因为我们提供了丰富的插件支持。
您可能也注意到了,我们的语言服务器可以被编译成webassembly并直接运行在浏览器中。如果你想只在在浏览器中体验 pivot-lang,可以访问https://pivotlang.tech。
vsc插件安装
在vsc插件市场搜索pivot-lang support,安装第一个即可
支持功能
-
vsc debug
- 断点
-
变量表
- 函数参数
- 普通变量
- 代码高亮
-
lsp支持
- 错误提示
-
代码提示
- 普通变量
- 函数参数
- 函数
- 类型
- 模块
-
代码跳转
- 普通变量
- 函数参数
- 函数
- 类型
- 模块
-
引用查找
- 普通变量
- 函数参数
- 函数
- 类型
- 语法高亮
References
语言功能的参考文档。
Pivot Lang基础语法和运算
函数定义
使用fn关键字定义函数,函数可以有返回值,也可以没有。
例如:
pub fn test_warn() void定义了一个没有返回值的函数pub fn test_vm_link() i64定义了一个返回值为i64类型的函数
变量定义和赋值
使用let关键字定义变量,并可以直接赋值。
例如:
let x = 1;定义了一个i64类型变量x并赋值为1let test: i8 = 1;定义了一个i8类型的变量test并赋值为1
运算
支持基本的算术运算(加减乘除)、位运算(与或非异或左移右移)等。
例如:
test = -test;是取反运算let test2: i8 = test + 1;是加法运算let b = test | 1;是位或运算
函数调用
直接使用函数名调用函数。
例如:
test_vm();调用了test_vm函数
指针操作
使用&获取变量的地址,使用*获取指针指向的值。
例如:
let b = &a;获取了变量a的地址*b = 100;修改了指针b指向的值
循环
使用while和for关键字进行循环。
例如:
while i < 7 {...}是一个while循环for let i = 0; i <= 10; i = i + 1 {...}是一个for循环
条件判断
使用if和else关键字进行条件判断。
例如:
if i == 3 {...}是一个if条件判断
跳出循环
使用break关键字跳出循环。
例如:
if i == 5 {break;}在i等于5时跳出循环
跳过当前循环
使用continue关键字跳过当前循环。
例如:
if i == 3 {i = 5;continue;}在i等于3时跳过当前循环
逻辑运算
支持基本的逻辑运算(与或非)。
例如:
let x = (false && true_with_panic()) || (true || !true_with_panic());是一个复杂的逻辑运算
Operators
本节收录了所有的运算符。
算术运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
+ | 加法 | 1 + 1 |
- | 减法 | 1 - 1 |
* | 乘法 | 1 * 1 |
/ | 除法 | 1 / 1 |
% | 取余 | 1 % 1 |
位运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
& | 与 | 1 & 1 |
\| | 或 | 1 \| 1 |
^ | 异或 | 1 ^ 1 |
<< | 左移 | 1 << 1 |
>> | 右移 | 1 >> 1 |
逻辑运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
&& | 逻辑与 | true && false |
\|\| | 逻辑或 | true \|\| false |
! | 逻辑非 | !true |
比较运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
== | 等于 | 1 == 1 |
!= | 不等于 | 1 != 1 |
> | 大于 | 1 > 1 |
< | 小于 | 1 < 1 |
>= | 大于等于 | 1 >= 1 |
<= | 小于等于 | 1 <= 1 |
赋值运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
= | 赋值 | a = 1 |
类型运算符
详见类型运算符。
| 运算符 | 描述 | 示例 |
|---|---|---|
as | 类型转换 | 1 as i32 |
is | 类型判断 | 1 is i32 |
impl | 实现 | a impl TestTrait? |
其他运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
& | 取地址 | &a |
* | 取值 | *a |
() | 函数调用 | test_vm() |
[] | 索引 | a[1] |
. | 成员访问 | a.b |
: | 类型标注 | let a: i32 = 1 |
; | 语句结束 | let a = 1; |
Type Operators 类型运算符
本章节会对三种特殊的运算符进行介绍:as、is 和 impl。
as 类型转换运算符
as 运算符用于将一个值转换为另一个类型。
基础类型转换
在转换一些基础类型的时候(比如int类型之间的转换),as 运算符是不会失败的,例如:
let a: i64 = 1;
let b: i32 = a as i32;
在这个例子中,a 是一个 i64 类型的变量,我们将其转换为 i32 类型的变量 b。这种转换永远成功,尽管可能会导致精度丢失或者损失一部分数据。
和类型转换
as也可以进行对和类型的转换,假设我们有如下类型:
struct ST{};
type Test<T> = T | ST;
我们可以将任意一个类型用as转换为Option类型:
let a: i64 = 1;
let b = a as Test<i64>;
将子类型转换为和类型是不可能失败的。如果尝试转化为一个不可能的类型,编译器会报错。
反之,as运算符也可以将和类型转换为子类型:
let a: i64 = 1;
let b = a as Test<i64>;
let c: i64 = b as i64!;
let d: Option<i64> = b as i64?;
但是,将和类型转换为子类型可能会失败,编译器不会允许你直接使用常规的as语句进行转换,你必须使用?或!来标注转换是非强制的还是强制的。
如果使用?标注,那么x as T?语句会返回一个Option<T>类型,如果转换失败,则该返回值是None。
如果使用!标注,那么x as T!语句会返回一个T类型,如果转换失败,则会导致运行时错误(__cast_panic)。
泛型类型转换
as运算符也可以用于泛型类型的转换:
fn test<T>(x: T) i64 {
let y = x as i64!;
return x;
}
如果泛型类型转换失败,会导致运行时错误(__cast_panic)。这种转换是编译期进行的,没有运行时开销。
泛型的转换一定是强制的,需要带上!标注。
if let ... as ... 语法
if let ... as ... 语法可以用于安全的对泛型类型进行转换:
fn test<T>(x: T) i64 {
if let y = x as i64 {
return y;
}
return -1;
}
is 类型判断运算符
基础类型判断
is 运算符用于判断一个值是否是某个类型。例如:
let a: i64 = 1;
let b = a is i64;
在这个例子中,b 的值是 true,因为 a 是一个 i64 类型的变量。
和类型判断
is 运算符也可以用于判断和类型:
let a: i64 = 1;
let b = a as Test<i64>;
let c = b is i64;
在这个例子中,c 的值是 true,因为 b 是一个 i64 类型的变量。
泛型类型判断
特殊的,is 运算符也可以用于判断泛型类型:
fn test<T>(x: T) T {
if x is i64 {
doSth();
}
return x;
}
impl 判断实现运算符
impl 运算符用于判断一个泛型是否实现了某个trait。例如:
trait TestTrait {
fn test();
}
struct TestStruct{};
impl TestTrait for TestStruct {
fn test() {
println("test");
}
}
fn test<T>(x: T) T {
let y = x impl TestTrait?;
let z = x impl TestTrait!;
z.test();
return x;
}
普通的impl语句必须带上?或!标注,否则编译器会报错。
对于?标注,如果泛型类型没有实现trait,那么语句会返回false,否则返回true。
对于!标注,如果泛型类型没有实现trait,那么语句会导致运行时错误(__impl_panic)。以上方例子举例,如果x没有实现TestTrait,那么let z = x impl TestTrait!;会导致运行时错误。反之,如果x实现了TestTrait,z将会是是一个特殊的T类型,但是他的增加了实现TestTrait的约束,使得下一行代码可以调用TestTraittrait的test方法。请注意,虽然z的类型和x的类型都是T,但是他们的约束是不同的,严格来说并不是同一类型。z的类型T,也不是上下文中的T类型。
if let ... impl ... 语法
if let ... impl ... 语法可以用于安全的对泛型类型进行trait实现判断:
fn test<T>(x: T) T {
if let y = x impl TestTrait {
y.test();
}
return x;
}
他等同于
fn test<T>(x: T) T {
if x impl TestTrait? {
let y = x impl TestTrait!;
y.test();
}
return x;
}
Pivot Lang数组使用说明
在Pivot Lang中,数组是一种重要的数据结构,可以用来存储多个相同类型的数据。以下是一些基本的数组操作:
创建数组
在Pivot Lang中,我们可以使用以下方式创建一个数组:
let a1:[i64] = [1];
let array = arr::from_slice([1, 2, 3]);
let b = a1[0];
a1[0] = 100;
这里,我们创建了一个名为a1的数组,它包含一个元素1。然后,我们使用arr::from_slice函数从一个切片创建了一个名为array的数组,它包含三个元素1、2和3。
原生的熟组是不能增加或减少元素的,但是可以使用arr::from_slice函数从一个切片创建一个数组容器,这个容器是可以增加或减少元素的。
访问数组元素
我们可以使用get方法来访问数组中的元素:
let a2 = array.get(2);
这里,我们获取了array数组中索引为2的元素,并将其值赋给了变量a2。
修改数组元素
我们可以使用set方法来修改数组中的元素:
array.set(2, 100);
这里,我们将array数组中索引为2的元素的值设置为了100。
添加元素到数组
我们可以使用push方法来向数组中添加元素:
array.push(4);
array.push(5);
这里,我们向array数组中添加了两个元素4和5。
从数组中移除元素
我们可以使用pop方法来从数组中移除元素:
let a5 = array.pop();
这里,我们从array数组中移除了最后一个元素,并将其值赋给了变量a5。
遍历数组
我们可以使用iter方法来获取一个数组的迭代器,然后使用next方法来遍历数组中的元素:
let iter = array.iter();
for let i = iter.next(); i is i64; i = iter.next() {
// 处理元素i
}
这里,我们获取了array数组的迭代器,然后使用一个循环来遍历数组中的元素。
Pivot Lang闭包使用说明
在Pivot Lang中,闭包是一种特殊的函数,它可以捕获和使用其外部作用域中的变量。以下是一些基本的闭包操作:
创建闭包
在Pivot Lang中,我们可以使用以下方式创建一个闭包:
let a = |a: i64| => i64 {
let c = b;
return c;
};
这里,我们创建了一个名为a的闭包,它接受一个i64类型的参数,返回一个i64类型的结果。在闭包体内,我们使用了外部作用域中的变量b。
调用闭包
我们可以像调用普通函数一样调用闭包:
let re = a(2);
这里,我们调用了闭包a,并将结果赋值给了变量re。
闭包的类型推断
在Pivot Lang中,一些情况下闭包的类型可以被推断出来。例如,我们可以将一个闭包作为函数的参数:
test_type_infer(|a| => {
let c = b;
return c;
});
这里,我们将一个闭包作为test_type_infer函数的参数。这个闭包接受一个参数a,并返回一个结果。在闭包体内,我们使用了外部作用域中的变量b。
返回闭包的函数
在Pivot Lang中,函数可以返回一个闭包:
fn test_ret_closure() |i64| => i64 {
let b = 1;
return |a: i64| => i64 {
let c = b;
return c;
};
}
这里,我们定义了一个名为test_ret_closure的函数,它返回一个闭包。这个闭包接受一个i64类型的参数,返回一个i64类型的结果。在闭包体内,我们使用了函数作用域中的变量b。
LSP特殊支持
所有闭包内部的被捕获变量都会被下划线标注,以方便区分
Module
模块化
模块的划分和使用
总体来说,pl的模块化与rust类似,但是规则比rust简单。
任何一个pl文件都是一个模块,模块的名字就是文件名。一个pl项目的根目录一定有Kagari.toml配置文件,之后所有该项目
模块的路径都是从该文件所在的目录开始计算的。
举个例子,如果我的pl项目有以下的目录结构:
test
├── Kagari.toml
├── mod1.pi
├── main.pi
└── sub
└── mod.pi
如果main.pi想使用mod1.pi或者mod.pi中的函数,那么可以这样写:
use mod1;
use sub::mod;
fn main() void {
mod1::func();
mod::func();
return;
}
如果mod.pi想使用mod1.pi中的函数,那么可以这样写:
use mod1;
fn main() void {
mod1::func();
return;
}
单独引入和全引入
pl的模块引入支持单独引入某些符号或者全引入。
use mod1::func1; // 单独引入
use mod2::*; // 全引入
请注意,单独引入仍然会形成父子模块关系,会对extension method的作用域产生影响。
引用另一个pl项目
目前只支持引用本地的pl项目,引用的方式是在Kagari.toml中添加[deps]
[deps]
sub3 = { path = "sub2" }
使用时,引用的项目模块会在deps中定义的命名空间之下:
use sub3::lib;
fn main() void {
lib::func();
return;
}
Method
method就是隶属于某个结构体的函数,它们与普通函数没有本质区别。
所有的method都必须在impl块里声明,且method都会隐式的有个self参数,该参数是impl类型的指针
Method Example
最简单的添加method的例子:
impl impl_struct {
pub fn add1() void {
self.x = self.x + 1;
return;
}
pub fn set(x: i64) void {
self.x = x;
return;
}
}
在一个包中,可以定义该包中结构体的method .
调用method的时候,使用<receiver类型>.<method>即可
let a = A{};
a.method();
Extension Method
实际上,如果一个结构体不在当前包中定义,我们可以仍然可以定义它实现 当前包中 Trait 的 method 。这种方法被称为extension method。
pub trait Eq<S> {
fn eq(r:*S) bool;
}
impl <T:Eq<T>> Eq<[T]> for [T] {
fn eq(r:*[T]) bool {
if arr_len(*self) != arr_len(*r) {
return false;
}
for let i = 0; i < arr_len(*self); i = i + 1 {
if !(*self)[i].eq(&(*r)[i]) {
return false;
}
}
return true;
}
}
当然,你也可以合法的为本包中的结构体实现子包(或本包)中的Trait,但是这种情况下的method不属于extension method。
与普通method的区别
extension method与普通method的区别在于其作用域,普通method的作用域与其所在的结构体相同,只要出现了该结构体类型就一定可以使用他的
method(这里的出现不止指显示的引入结构体,通过函数返回值等方式间接的获取该类型的值也算)。
而extension method的作用域则是在Trait所在的包中,要使用extension method,必须直接或者间接的依赖了该Trait所在的包。
Pivot Lang Trait 语法和功能
在 Pivot Lang 中,trait 是一种定义共享行为的方式。一个 trait 可以由多个方法组成,这些方法定义了实现该 trait 的类型应具有的行为。
Trait 定义
一个 trait 是使用 trait 关键字定义的,后面跟着 trait 的名称和一个包含方法签名的代码块。例如:
trait B {
fn b() i64;
}
这定义了一个名为 B 的 trait,它有一个返回 i64 的方法 b。
复合 Traits
一个 trait 可以要求实现它的类型也实现其他的 traits。这是通过 : 操作符完成的。例如:
trait C: A+B {
fn c() void;
}
这定义了一个名为 C 的 trait,要求实现它的类型也要实现 A 和 B 这两个 traits。
Trait 实现
一个类型通过为 trait 中的所有方法提供定义来实现一个 trait。这是通过 impl 关键字完成的。例如:
impl B for test_struct {
fn b() i64 {
return 1000;
}
}
这段代码为类型 test_struct 实现了 trait B。方法 b 被定义为返回 1000。
关于 impl 的更多信息,请参阅 method。
Trait 使用
一个 trait 可以被用作变量和函数参数的类型。这允许代码与实现了该 trait 的任何类型一起工作。例如:
let c: C;
这段代码声明了一个类型为 C 的变量 c。任何实现了 trait C 的类型都可以被赋值给 c。
结论
Pivot Lang 中的 traits 提供了一种定义类型间共享行为的方式。它们允许代码重用和多态,使得语言更加灵活和强大。
Pivot Lang 泛型语法和功能
在 Pivot Lang 中,泛型是一种定义可以处理多种类型的代码的方式。泛型可以用于定义函数、结构体和trait。在定义时,泛型参数被指定为特定的标识符,这个标识符可以在定义中的任何地方使用。在使用泛型定义的代码时,泛型参数被具体的类型替换。
以下是一些使用泛型的例子:
1. 在结构体中使用泛型:
pub struct HashTable<G:Hash+Eq<G>|V> {
buckets:[Option<TableNode<G|V>>];
salt:u64;
entries:u64;
}
在这个定义中,K和V是泛型参数。K必须实现Hash和Eq<K>这两个trait,V没有特定的要求。HashTable有三个字段:buckets、salt和entries。buckets是一个数组,它的元素类型是Option<TableNode<K,V>>,这是一个使用泛型参数K和V的类型。
2. 在方法中使用泛型:
impl <K:Hash+Eq<K>|V> HashTable<K|V> {
pub fn insert(k:K,v:V) void {
// ...
}
}
在这个方法中,K和V是泛型参数。这个方法接受两个参数,一个是类型为K的键,一个是类型为V的值。
3. 在普通函数中使用泛型:
pub fn new_hash_table<K:Hash+Eq<K>|V>(bucket_size:u64,salt:u64) HashTable<K|V> {
// ...
}
在这个函数中,K和V是泛型参数。这个函数接受两个参数,一个是桶的大小,一个是盐值。它返回一个HashTable<K,V>类型的值。
4. 使用trait约束:
在Pivot Lang中,可以使用trait约束泛型参数。例如,K:Hash+Eq<K>表示K必须实现Hash和Eq<K>这两个trait。
泛型提供了代码重用的强大工具,使得可以编写一段代码来处理多种类型,而不是为每种类型都写一段几乎相同的代码。这不仅可以减少代码量,也可以提高代码的可读性和可维护性。
Pivot Lang 元组语法和功能
在 Pivot Lang 中,元组是一种可以包含不同类型元素的数据类型。元组使用圆括号()包围元素,元素之间使用逗号,分隔。元组的元素可以通过.后跟索引的方式访问。
以下是一些使用元组的例子:
1. 定义一个空元组:
let d = ();
2. 定义一个只有一个元素的元组:
let a = (1,);
注意,只有一个元素的元组需要在元素后面加上逗号,,否则它会被认为是一个普通的值,而不是元组。
3. 定义一个包含多个元素的元组:
let b = (1, 2);
4. 定义一个包含元组的元组:
let c = (1, 2, (3,));
- 访问元组的元素:
let e = a.0;
let f = c.2;
在这些例子中,a.0表示元组a的第一个元素,c.2表示元组c的第三个元素。
Deconstruct
解构指的是用类似构造复杂类型的语法获取复杂类型中的部分值。一般来说,解构语法会用于结构体和元组。
Table of Contents
元组解构
let (a, b, c) = (1, 2, 3);
(a, b, c): (i32, i32, i32) = (1, 2, 3);
(a) = (1,);
let (a, b, c) = (1, 2); // 出错!
(a) = (1, 2); // 出错!
结构体解构
结构体解构与元组解构类似,只是解构的时候需要指定字段名。
struct Point {
x: i32;
y: i32;
}
let { x:xx, y:yy } = Point { x: 1, y: 2 };
struct Point {
x: i32;
y: i32;
}
let { x, y } = Point { x: 1, y: 2 }; // 省略字段名
let yy:i32;
{ x, y:yy } = Point { x: 1, y: 2 };
对于结构体解构,你不需要像元组一样解构所有的字段。
struct Point {
x: i32;
y: i32;
}
let { x } = Point { x: 1, y: 2 }; // 只解构 x 字段
嵌套解构
解构语法可以嵌套使用。
struct Point {
x: i32;
y: i32;
}
struct Line {
start: Point;
end: Point;
}
let { start: { x:xx, y:yy }, end: { x:xx2, y:yy2 } } = Line { start: Point { x: 1, y: 2 }, end: Point { x: 3, y: 4 } };
元组和结构体也可以相互嵌套
struct Point {
x: i32;
y: i32;
}
struct Line {
start: Point;
end: Point;
}
let (a, b, { start }) = (1, 2, Line { start: Point { x: 1, y: 2 }, end: Point { x: 3, y: 4 } });
Pivot Lang的Union语法
在Pivot Lang中,Union类型允许你将多种不同的类型组合在一起。你可以定义一个Union类型,它可以包含任何你需要的类型。以下是一些Union类型的定义:
type A<T> = f32 | T;
type B<T> = i32 | A<T>;
type D = *i32 | f64;
在上述代码中,A是一个泛型Union类型,它可以是f32或者任何其他类型T。B也是一个泛型Union类型,它可以是i32或者类型A。D是一个Union类型,它可以是*i32或者f64。
你可以使用Union类型来定义变量,如下所示:
let c: A<i128> = a;
let aa: B<i128> = d;
let ff: D = ≫
你也可以使用Union类型在函数中作为返回值,如下所示:
fn test_ret_union() Option<i64> {
return 101;
}
你还可以在Union类型上定义方法,如下所示:
impl<T> A<T> {
fn name() void {
let f = (*self) as f32!;
f = 100.0;
return;
}
}
此外,你还可以在函数中使用Union类型作为参数,如下所示:
fn generic<R>(a: Option<R>) void {
let c = a as R!;
a = c;
return;
}
Union与其子类型转化
隐式类型转化
隐式转化主要出现在赋值操作中。例如:
#![allow(unused)] fn main() { let c: A<i128> = a; }
在这行代码中,变量 a 的类型是 i128,在赋值给 c 时,它被隐式转化为 A<i128> 类型。这是因为 A<i128> 类型包含了 i128 类型,所以 i128 类型可以被隐式转化为 A<i128> 类型。
显式类型转化
显式类型转化主要通过 as 关键字进行。例如:
#![allow(unused)] fn main() { let h = c as i128?; }
在这行代码中,变量 c 的类型是 A<i128>,使用 as 关键字将其显式转化为 Option<i128> 类型。因为 A<i128> 类型包含了 i128 类型,但是她不一定是 i128 类型,所以 A<i128> 类型可以被安全的显式转化为 Option<i128> 类型。
强制类型转化
强制类型转化通过 as ... ! 符号进行。例如:
#![allow(unused)] fn main() { let i = c!; }
在这行代码中,变量 c 的类型是 A<i128>,使用 ! 符号将其强制转化为 i128 类型。这是因为 A<i128> 类型包含了 i128 类型,所以 A<i128> 类型可以被强制转化为 i128 类型。
Macro
TODO
环境准备
Rust
可以在项目的根目录下的rust-toolchain文件中查看当前项目使用的rust版本,如果你的rust版本不是这个版本,可以使用rustup安装这个版本的rust。
rustup install $(cat rust-toolchain)
国内如果没代理安装rust比较困难,建议使用清华源进行安装,见此处
安装完毕后,可以进行cargo换源设置,防止依赖无法下载,见此处
LLVM
Pivot-Lang目前使用LLVM 18作为后端,所以需要安装LLVM。如果你使用的是MacOS,可以使用brew安装LLVM。
brew install llvm@18
如果你使用的是ubuntu,可以使用这里的脚本进行安装
CMake
我们的垃圾回收模块使用了LLVM中的StackMap功能,需要使用CMake进行编译。
环境变量
开发项目需要正确配置一些环境变量才能让你保证开发时正确跑通测试。
运行下方命令将会把项目需要的一些环境变量加入到你的初始化脚本中
make devlinux # linux
make devmac # mac
注意这些命令都只需要跑一次
测试是否成功配置开发环境
上方步骤完成后,可以运行下方命令进行测试
make test
如果上方命令都成功执行,那么恭喜你,你已经成功配置了开发环境
使用github codespace 进行开发
使用github codespace进行开发的环境配置较为简单,但是请注意费用问题。
点击以下链接即可创建一个包含pl开发环境的codespace
创建完毕后,建议使用本地vscode打开codespace中的项目进行开发
常见问题
No suitable version of LLVM was found system-wide or pointed
需要设置llvm环境变量,如果你使用的是ubuntu,可以执行如下脚本.
echo "export LLVM_SYS_180_PREFIX=/usr/lib/llvm-18" >> ~/.bashrc
source ~/.bashrc
如果是macOS通过brew install llvm@16安装,则需要设置环境变量:
echo "export LLVM_SYS_180_PREFIX=$(brew --prefix llvm@18)" >> ~/.bashrc
source ~/.bashrc
Could NOT find ZLIB (missing: ZLIB_LIBRARY ZLIB_INCLUDE_DIR)
缺少zlibdev造成的,如果你是ubuntu机器,使用下方命令进行安装:
sudo apt install zlib1g-dev
Unknown linker flag: -lzstd
在Mac上出现时,可能是缺少LIBRARY_PATH环境变量
echo "export LIBRARY_PATH=$LIBRARY_PATH:$(brew --prefix zstd)/lib" >> ~/.bashrc
source ~/.bashrc
Compiler
本文档会总体介绍一遍Pivot-Lang编译器的整体工作流程,帮助开发人员快速上手开发。
编译器基本工作流程
graph LR
A[Source Code] --> C[nom parser]
C --> D[AST]
D --> E[LLVM backend]
E --> F[Object File]
F --> |linker| G[Executable File]
Nom parser
nom parser包含了编译器的词法分析和语法分析部分。nom parser的主要功能是使用递归下降法将pivot-lang源代码转换为ast。
A Basic Tour of nom
nom库是纯粹的函数式思想,对于接触函数式比较少的同学可能第一次看到会一脸懵,不过其实他的用法并不困难。 第一次看到nom这种函数式的代码就能自己搞懂函数式编程的思路是很难的,但是你肯定能轻松做到看懂下方教程中的parse 样例。当你看懂了下方的例子再去看我们parser的源码,我相信你只要花一些时间就能搞懂大部分的内容
nom本质是一系列封装好的parser函数和处理parser的函数(被称为combinator)的集合,所有的parser函数都有类似的泛型签名,例如他们的返回值一定是:
Result<(I, O), E>
parser函数一般是一个泛型函数,拥有三个类型参数 I,O 和 E ,分别代表输入的类型,输出的类型和错误的类型。其中,I 是指输入的类型,通常在编译器中输入的数据类型是 Span。E 的类型是 (),因为在编译器中为了进行错误容忍我们一般不会在parse阶段抛出任何错误。O 的类型是我们构建的语法树的节点类型,它应该反映输入中提供的语言结构。在 parser 函数中,函数的输入参数类型通常是一个类型为I的值,并且输出的内容中的 I 表示自身处理后剩余的未处理内容。
举例来说,nom中的tag函数能产生一个接受指定值的parser:
let parser = tag("123")
let (remain, output) = parser("12345").unwrap();
assert_eq!(remain, "45");
assert_eq!(output, "123");与parser相对应的是combinator,它们的输入参数一般是一个或一组parser组成,他们对自己参数中的parser进行组装并按照自己的规则产生新的parser。上方例子中的tag函数就是一种特殊的combinator,它的输入参数是一个字符串,它的输出是一个parser,这个parser只能parse在tag参数中指定的字符串。
nom中的combinator非常多,这里只介绍一些常用的combinator。
// preceded: 接受两个parser,按照顺序执行,返回第二个parser的结果,第一个parser结果被丢弃
let parser = preceded(tag("123"), tag("456"));
let (remain, output) = parser("1234567").unwrap();
assert_eq!(remain, "7");
assert_eq!(output, "456");
// map_res: 接受一个parser和一个函数,将parser的结果作为函数的输入,返回函数的输出
let parser = map_res(tag("123"), |s: &str| s.parse::<i32>());
let (remain, output) = parser("1234567").unwrap();
assert_eq!(remain, "4567");
assert_eq!(output, 123); // 输出被map_res变为了i32类型,这个combintor经常被用于生成ast node
// alt: 接受多个parser,按照顺序执行,返回第一个成功的parser的结果
let parser = alt((tag("123"), tag("456")));
let (remain, output) = parser("4567123").unwrap();
assert_eq!(remain, "7123");
assert_eq!(output, "456"); // 第一个parser失败,第二个成功,返回第二个parser的结果
选择合适的combinator是编写parser的关键,nom提供了一些文档:
AST
AST是抽象语法树的简称,是编译器的中间表示。AST是由nom parser生成的,它是一个树形结构,每个节点都是一个结构体,包含了节点的类型、子节点、行号、列号等信息。
Builder
我们在某次重构中尝试分离了编译后端和AST相关的逻辑,虽然在别的包目前还有一些和llvm代码的耦合,但是理论上我们已经可以添加别的编译后端,
只要该后端能被封装成实现builder trait的类型即可。
目前我们有两个后端,一个是LLVM,一个是NoOp,LLVM是目前唯一有真正编译能力的后端,NoOp是一个空后端,它实际上不干 任何工作,它被用于lsp运行模式,因为lsp模式下不需要真的进行编译,使用该后端能增加lsp的性能。
需要注意的点
1. 差量分析
所有被salsa的proc macro标记的函数都是支持差量运行的。这些函数要求必须是纯函数,他们的输入输出应该看作是只读的,
即使里面存在例如Arc<Refcell<xxx>>一类的字段,你也不该在外界对其进行borrow_mut然后修改。
如果改了可能导致非常难查出来的bug。
Parser
parser源代码位置位于src/nomparser目录下,包含了词法分析和语法分析部分。
nom
nom是一个用rust编写的parser combinator库,它不像lr分析器一样提供生成代码的功能,而是 提供一组函数,这些函数可以用来组合出各种parser。
相比于lr分析器,nom的优点是它的parser combinator非常灵活,熟练后可以快速组合出各种parser, 而且可自定义性非常的强,看起来也很直观,相比很多ir生成器的语法并没有复杂多少,但是带来了更好的 语法支持(一般的ir分析生成器的语法定义文件不会有编程语言那么好的语法支持)。
会使用nom是读懂编译器parser代码的重要前提,这里强烈推荐两个nom文档:
parser结构
parser的主要功能是使用递归下降法将pivot-lang源代码转换为ast。如果你不了解递归下降法,可以先看看这篇文章。
对于pivot lang的每一条语法规则,都会在parser里对应一个分析函数,这些分析函数可能会调用其他分析函数,最终最上层的分析函数可以将完整的源代码转换为ast。
pivot lang的完整语法规则见这里
parser最顶层的函数是parse,它接受一个源文件输出一个AST根节点。
/// # parse
///
/// parse parses the file contents specified by source by the pivot-lang syntax,
/// and returns the node representation of the file as a [ProgramNodeWrapper].
/// the `parse` doesn't attempt to read the other files besides the provided file.
#[salsa::tracked]
pub fn parse(db: &dyn Db, source: SourceProgram) -> Result<ProgramNodeWrapper<'_>, String> {
let text = source.text(db);
let re = program(Span::new_extra(text, Default::default()));
match re {
Err(e) => Err(format!("{:?}", e)),
Ok((i, node)) => {
log::info!("parse {:?}", source.path(db));
Diagnostics((source.path(db).to_string(), i.extra.errors.borrow().clone()))
.accumulate(db);
Ok(ProgramNodeWrapper::new(db, node))
}
}
}AST
抽象语法树是目前编译器中最复杂的部分,它是编译器的中间表示,也是编译器的核心。本节将介绍AST的设计和实现。
AST的设计
基本上,所有源代码中的基础单位都会对应抽象语法树中的一个节点。抽象语法树有很多类型的节点,他们可能会相互引用。
所有的节点都必须实现Node trait,这个trait定义了节点的基本行为。
#[enum_dispatch]
pub trait Node: RangeTrait + FmtTrait + PrintTrait {
fn emit<'a, 'b>(
&mut self,
ctx: &'b mut Ctx<'a>,
builder: &'b BuilderEnum<'a, '_>,
) -> NodeResult;
}
/// print trait to report the AST node structure
#[enum_dispatch]
pub trait PrintTrait {
fn print(&self, tabs: usize, end: bool, line: Vec<bool>);
}
一般来说,所有的节点都需要加入NodeEnum中,并且使用#[node]proc macro进行修饰。
同时需要在fmt.rs中加入format相关的函数。
如果你想学习如何添加新的节点,可以先从简单的节点开始,比如BoolConstNode
#[node]
pub struct BoolConstNode {
pub value: bool,
}你可能注意到了,Nodetrait继承了RangeTrait,这个trait定义了节点的位置信息。
#[enum_dispatch]
pub trait RangeTrait {
fn range(&self) -> Range;
}一般来说,RangeTrait的实现通过#[node]宏来自动生成,你不需要手动实现它。
Node接口中的print函数用于打印节点的信息,它会被用于调试。print打印的结果和tree的输出非常像,你需要用一些工具函数来
格式化输出。以ifnode的print函数为例:
#![allow(unused)] fn main() { fn print(&self, tabs: usize, end: bool, mut line: Vec<bool>) { deal_line(tabs, &mut line, end); tab(tabs, line.clone(), end); println!("IfNode"); self.cond.print(tabs + 1, false, line.clone()); if let Some(el) = &self.els { self.then.print(tabs + 1, false, line.clone()); el.print(tabs + 1, true, line.clone()); } else { self.then.print(tabs + 1, true, line.clone()); } } }
emit函数是生成llvm代码的核心,它会调用llvm api构造自己对应的llvm ir。在编译的时候,最上层节点的emit会被调用,
该函数会递归的调用自己的子节点的emit函数,最终生成整个程序的llvm ir。
下方是ifnode的emit函数:
fn emit<'a, 'b>(
&mut self,
ctx: &'b mut Ctx<'a>,
builder: &'b BuilderEnum<'a, '_>,
) -> NodeResult {
let cond_block = builder.append_basic_block(ctx.function.unwrap(), "if.cond");
let then_block = builder.append_basic_block(ctx.function.unwrap(), "if.then");
let else_block = builder.append_basic_block(ctx.function.unwrap(), "if.else");
let merge_block = builder.append_basic_block(ctx.function.unwrap(), "if.after");
builder.build_unconditional_branch(cond_block);
ctx.position_at_end(cond_block, builder);
let cond_range = self.cond.range();
let (gen_def, skip_body) = cond_pre_process(
&mut self.cond,
ctx,
builder,
then_block,
else_block,
cond_range,
);
// emit the else logic into the then block
ctx.position_at_end(then_block, builder);
let mut then_terminator = TerminatorEnum::None;
// emit the code inside a child context because it belongs to a sub-block
let mut child = ctx.new_child(self.then.range().start, builder);
if !skip_body || matches!(builder, BuilderEnum::NoOp(_)) {
if let Some(mut def) = gen_def {
def.emit(&mut child, builder)?;
}
then_terminator = self.then.emit(&mut child, builder)?.get_term();
}
if then_terminator.is_none() {
// there is no terminator(like return, yield and so forth) in the statement
// create an unconditional branch to merge block to finish off the "then" block
builder.build_unconditional_branch(merge_block);
}
// emit the else logic into the else block
ctx.position_at_end(else_block, builder);
let terminator = if let Some(el) = &mut self.els {
let mut child = ctx.new_child(el.range().start, builder);
let else_terminator = el.emit(&mut child, builder)?.get_term();
if else_terminator.is_none() {
// create an unconditional branch only if no terminator is detected
// otherwise, the code to be executed might be the others instead of merge block
// for example, if there is a 'return' statement in the if-then-else clause,
// it won't execute the merge block as it returns directly
builder.build_unconditional_branch(merge_block);
}
if then_terminator.is_return() && else_terminator.is_return() {
TerminatorEnum::Return
} else {
TerminatorEnum::None
}
} else {
builder.build_unconditional_branch(merge_block);
TerminatorEnum::None
};
ctx.position_at_end(merge_block, builder);
if terminator.is_return() {
builder.build_unconditional_branch(merge_block);
}
ctx.emit_comment_highlight(&self.comments[0]);
NodeOutput::default().with_term(terminator).to_result()
}emit函数的第一个参数是节点自身,第二个参数是编译上下文。编译上下文中会包含一些需要透传的信息,比如符号表,lsp参数等,
第三个参数是builder,用于生成中间代码。目前builder只有llvm的实现。
emit函数的返回值比较复杂,它是一个Result枚举类型,它的Ok类型中包含一个Option的PLValue--这是代表该节点的运算结果,
一般只有表达式节点有这个值,statement节点这里会返回None,除此之外还包含一个Option的PLType,这是代表该节点返回值的类型,
最后一个是一个TerminatorEnum,用于分析某个路径是否有终结语句(break,continue,return,panic等)。返回值的Err类型是一个PLDiag,这个类型是用于报告错误的,包含了所有的错误信息。一般来说,在返回之前错误就会被加到编译上下文中,所以调用者不需要对其进行
任何处理。
打印AST结构
plc命令行工具有打印ast的功能,你可以使用plc xxx.pi --printast命令来打印ast结构。
下方是一个ast打印结果的样例:
...
file: /Users/bobli/src/pivot-lang/test/sub/mod.pi
ProgramNode
└─ FuncDefNode
├─ id: name
├─ TypeNameNode
│ └─ ExternIdNode
│ └─ VarNode: void
└─ StatementsNode
└─ RetNode
file: /Users/bobli/src/pivot-lang/test/mod2.pi
ProgramNode
├─ UseNode
│ ├─ VarNode: sub
│ └─ VarNode: mod
├─ FuncDefNode
│ ├─ id: test_mod
│ ├─ TypedIdentifierNode
│ │ ├─ id: args
│ │ └─ TypeNameNode
│ │ └─ ExternIdNode
│ │ └─ VarNode: i64
│ ├─ TypeNameNode
│ │ └─ ExternIdNode
│ │ └─ VarNode: void
│ └─ StatementsNode
│ └─ RetNode
└─ StructDefNode
├─ id: Mod2
└─ TypedIdentifierNode
├─ id: y
└─ TypeNameNode
└─ ExternIdNode
└─ VarNode: bool
...
Flow Chart
这是一个附加功能,它将为每个函数生成流程图,以 .dot 文件格式输出,.dot 文件可通过
查看。
依赖
实现
流程图的生成包含两个步骤:
- 由 AST 生成
图数据结构 - 根据
图生成.dot文件
图的生成
我们以函数为单位生成 graph ,而 AST 根节点为 ProgramNode,因此我们需要遍历其 fntypes
,逐个生成 graph 最终得到一个 Vec :
impl ProgramNode {
pub fn create_graphs(&self) -> Vec<GraphWrapper> {
let mut graphs = vec![];
for func in &self.fntypes {
if let Some(body) = func.body.clone() {
let graph = from_ast(Box::new(NodeEnum::Sts(body)));
graphs.push(GraphWrapper {
name: func
.id
.name
.clone()
.replace(|c: char| !c.is_ascii_alphanumeric(), "_"),
graph,
});
}
}
graphs
}
}接下来实现 from_ast() 函数,它接收一个 NodeEnum(这是一个 Statements 节点), 返回一个完整的 Graph,具体分为两步:
- 初步构建图(
build_graph()) - 去除不必要节点(
0入度节点,虚节点,空节点))
pub fn from_ast(ast: Box<NodeEnum>) -> Graph {
let mut ctx = GraphContext::new();
build_graph(ast, &mut ctx);
// 删除入度为 0 的节点
while remove_zero_in_degree_nodes(&mut ctx.graph) {}
// 删除虚节点
while remove_single_node(&mut ctx.graph, |_, t| *t == GraphNodeType::Dummy) {}
// 删除空节点
let remove_empty_nodes: fn(NodeIndex, &GraphNodeType) -> bool = |_, t| match t {
GraphNodeType::Node(t) => t.is_empty() || t.trim() == ";",
_ => false,
};
while remove_single_node(&mut ctx.graph, remove_empty_nodes) {}
ctx.graph
}主要介绍构建图的环节。
定义图的 节点 与 边 :
#[derive(Debug, Clone, PartialEq, Eq)]
pub enum GraphNodeType {
Dummy, // 虚节点
Begin, // 起点
End, // 终点
Node(String), // 普通节点
Err(String, String), // 错误节点
Choice(String), // 选择节点
}
#[derive(Debug, Clone, Copy)]
pub enum EdgeType {
Normal,
Branch(bool), // 分支,带有 Y/N 等标签
}
pub type Graph = StableDiGraph<GraphNodeType, EdgeType>;build_graph()函数以 Statement 为单位,针对不同节点构建不同的图结构,为了方便的连接节点,我们定义了 GraphContext 用于存储上下文信息:
struct GraphContext {
pub graph: Graph,
pub break_target: NodeIndex,
pub continue_target: NodeIndex,
#[allow(dead_code)]
pub global_begin: NodeIndex, // 全图起点
pub global_end: NodeIndex, // 全图终点
pub local_source: NodeIndex, // 局部起点
pub local_sink: NodeIndex, // 局部终点
}每次调用 build_graph() 前,我们需要为构建部分提供两个 锚点(local_source, local_sink) ,第一次调用时,锚点 即为起点和终点,
以后每次调用前,均需构建两个虚节点,作为锚点(虚节点之后将被去掉)。
对于不涉及分支、循环、跳转的简单语句,图结构较为简单:
local_source -> current -> local_sink
local_source ------------> local_sink // 注释
local_source ---> ERR ---> local_sink // 错误
分支及循环语句则较为复杂(以 IF语句 为例):
IF: /--Y--> sub_source -----> [...body...] ------> sub_sink ->-\
/ \
local_source -> cond local_sink
\ /
\--N--> sub_source1 -> Option<[...els...]> -> sub_sink ->-/
if.body 及 if.els 部分可以通过递归调用 build_graph() 构建,但是需要先生成两个虚节点,并暂时赋给 ctx,构建完毕后,
ctx 的 local_source/sink需要还原
对于语句块,对每个语句调用 build_graph() ,每次将 sub_source 更改为 sub_sink ,sub_sink 则重新创建:
for i in &v.statements {
context.local_source = sub_source;
context.local_sink = sub_sink;
build_graph(i.clone(), context);
if i != v.statements.last().unwrap() {
sub_source = sub_sink;
sub_sink = context.graph.add_node(GraphNodeType::Dummy);
}
}.dot 文件生成
我们只需按dot语法格式生成图的点/边的信息即可。下面是一个简单的dot文件:
digraph _pointer_struct__name_params {
D0 [shape=box, style=rounded, label="begin", fontname=""];
{rank = sink; D1 [shape=box, style=rounded, label="end", fontname=""];}
D4 [shape=box, label="return\l", fontname=""];
D4 -> D1;
D0 -> D4;
}
可以在Graphviz Online查看对应流程图。
Language Server
Pivot Lang的Language Server(以下简称LSP)是一个用于为编译器提供语法支持的组件,它同时被用于在编译期间生成诊断信息。
基本上,lsp能够为所有的现代代码编辑器提供服务,但是目前我们只为vsc提供官方支持。如果想在别的编辑器中使用lsp,可能需要自己写一个 简单的客户端插件。
⚠️注意事项
有一些函数功能纯粹,可能被用在很多无法预料的地方,如果在这些函数中操作非幂等的lsp相关功能很可能导致lsp最后工作时出现错误,请尽量避免!
目前大部分lsp的功能接口都是幂等的。semantic_token和doc_symbol不幂等
设计(design)
pivot-lang的lsp功能被内置于编译器中,它是以差量计算(incremental)为前提设计的。 目前整个lsp程序几乎是完全单线程的,但得益于我们的差量计算,它仍然具有不错的性能。
1. 差量计算(incremental)
差量计算是指在编译器中,当源代码发生修改时,我们只对发生变化的部分进行重新分析,而不是对整个项目全部重新进行计算。
pivot-lang的差量计算是基于rust的salsa库实现的。
我们使用的版本是仍然处于预览阶段的salsa_2022。
pl中的差量计算的最小复用单元是Module,即一个源文件。
在plc作为lsp运行时,所有的lsp功能相关计算会在TextDocumentEdit事件发生时进行,之后如果不进行文本编辑,所有的
lsp请求都会直接从缓存中读取结果。
2. 差量计算举例
假设我们有一个pl项目,其中有三个文件:a.pi、b.pi、c.pi。
其中a.pi和b.pi都引用了c.pi中的函数f,并且a.pi中还使用了b.pi中的函数g。
此时,当我们用vsc打开此pl项目,vsc会启动plc进行分析。如果没使用差量计算,那么plc分析流程如下:
尝试分析a.pi->
依赖c.pi->
分析c.pi->
返回继续分析a.pi->
依赖b.pi->
分析b.pi->
依赖c.pi->
分析c.pi->
返回继续分析b.pi->
返回继续分析a.pi->
完成
可以看到c.pi被分析了两次,这是不必要的。差量分析在这一步中可以优化掉第二次对c.pi的分析。
然后,假设我们在a.pi中添加了一个字符,那么如果没采用差量分析法,所有的模块都会被重新分析一遍。而差量分析法只会对a.pi进行重新分析。
接着,如果我们改动了b.pi,那么差量分析法会对b.pi和a.pi进行重新分析,而不会对c.pi进行重新分析。即:每次修改文件时,只会对该文件以及依赖该文件的文件进行重新分析。
3. 验证差量计算是否正常工作
我们可以在vsc的选项中找到一个plc的Log Level选项,将它设置成2之后就能看到plc的info日志了。
日志可以在vsc的outut中选择
pivot-lang language server查看
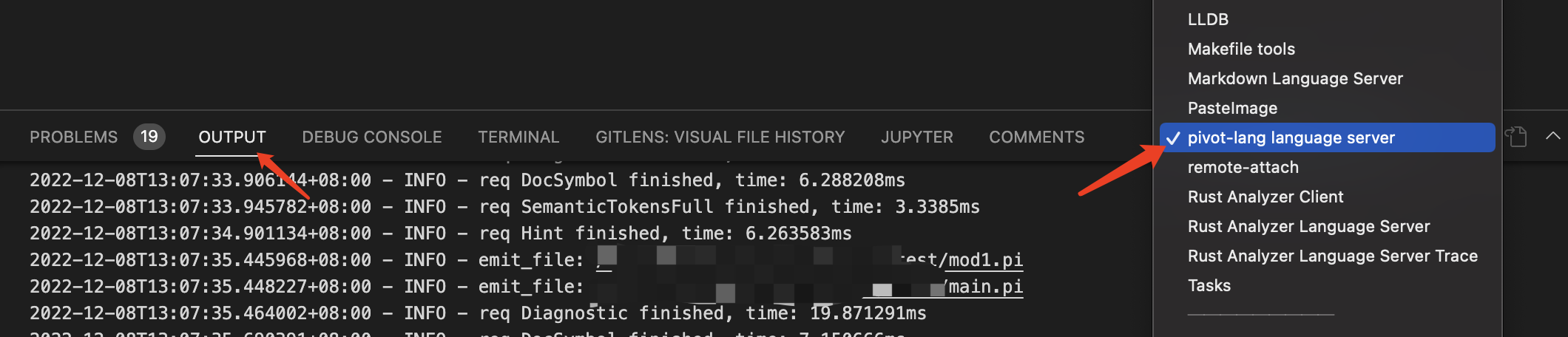
这里会在每次重新计算的时候输出对应的log。
Diagnostic
诊断信息是个非常重要的功能,它可以帮助我们在编写代码的时候发现错误和可能有问题的地方,从而提高我们的编码效率。
为了让用户体验尽可能的好,我们的lsp分析需要尽量容忍用户的错误输入,尽可能多的分析出用户代码中的问题
Fault Tolerance
错误容忍是生成好的诊断信息的前提。在pivot-lang的中,我们分别在两个层面上实现了错误容忍:
- parser
- ast
Parser的错误容忍
nom parser架构中,如果出现了一个无法被识别的语句,整个分析器就会终止分析输出错误。这对于错误容忍的要求来说是无法被接受的。所以 我们的编译器不使用nom parser的默认错误处理机制,任何parser阶段产生的nom error都应该被视作bug,我们应该尽可能的避免这种情况。
在parse过程中,如果一些错误语句能非常明显的被识别为一个语法的未完成项(且没有歧义),我们应该将它识别为该语法类型的Node,并且在Node上加一个
flag标识它不完整(常常是is_complete),这样在ast阶段我们就能输出对应的诊断信息。
对于最常见的基础语法单位statement和top_statement,parser提供了一个helper函数except,能够在遇到不可被识别的错误语句的时候
将该“块”语句识别为ErrNode,以方便后续的分析正常进行。
!!!注意:ErrNode虽然很好用,但是它只能输出很宽泛的诊断信息(比如无法识别该语句),它是最后的错误容忍手段,应该尽量避免使用它
AST的错误容忍
由于parse阶段的时候能够容忍错误的语句,对于一些语法错误,ast节点只需要检查自身的完整性就能够输出诊断信息了。而对于语义错误(例如类型不匹配),我们需要在ast阶段
进行分析并获取结果。这些操作目前是在各个节点的emit函数里进行的。所有的emit函数都返回NodeResult类型,如果该节点的emit中出现了错误,
分析将会中断,其对应的错误信息会被添加到ctx(编译上下文)中并且作为error返回。上层函数如果遇到自己依赖的函数报错一定不能重复添加该错误至ctx中,
否则会导致错误信息重复输出。上层函数处理自己的依赖报错有两种情况:
- 直接停止分析并将该错误传递给自己的上级
- 忽略该错误继续进行分析
一般来说,大部分的expression和statement都会采用第一种方案,而statement block则会采用第二种方案
SystemLib
pl的系统库一部分是pl代码一部分是rust代码,rust部分在项目的vm目录中,pl部分在planglib目录中。
VM
放rust写的给pivot-lang使用的函数
所有导出的函数需要加#[is_runtime],所有导出结构体需要加#[repr(C)]
JIT invalid memory access issue
在jit模式下使用runtime函数可能会出现invalid memory access错误,
这个问题本质是rust编译的时候会优化掉不使用的module,导致jit时找不到对应runtime函数。所以建议每个
mod加一个叫做reg的函数,里边必须用到你会使用的所有结构体,这样在需要jit测试的时候调用使用模块的reg函数,对应代码就不会被优化掉了。
使用is_runtime导出rust函数
一个被is_runtime标记的rust函数在编译到静态库之后,在pivot-lang中声明对应的函数,即可像正常函数一样调用。例如:
Rust:
#![allow(unused)] fn main() { #[is_runtime] fn printi64ln(i: i64) { println!("{}", i); } }
Pivot Lang:
fn printi64ln(i: i64) void
fn main() void {
printi64ln(1)
return
}
!!!注意事项:
is_runtime标记的函数不能有modifier(比如pub,unsafe),但是被is_runtime标记的impl块中的函数不受此限制。struct MyStruct; #[is_runtime("struct")] impl MyStruct { pub fn myfunc1() { // ... } }标记impl块时,导出的函数名称会变为
{structname}__{fnname}的形式,函数允许使用receiver。更多高级用法参见is_runtime的rust doc
GC
pivot-lang 是一门使用gc进行内存管理的语言。
pivot-lang 的gc目前是使用rust写的,采用一种叫做immix[[1]](https://www.cs.utexas.edu/users/speedway/DaCapo/papers/immix-pldi-2008.pdf)的mark region算法。
在以前的版本中,我们使用的是我们现在叫做simple gc的垃圾回收算法,他是一个简单的mark-sweep算法。
它由于性能问题和不支持多线程等原因最终被immix取代。
Immix GC
immix gc是一种mark region算法,它是一个精确的gc算法。但是请注意,它的精确建立在使用它 的项目提供的特殊支持之上。可以认为目前我们的immix gc实现 是为pivot-lang量身定制 的。pl编译器为了和我们的immix gc配合,会在编译时专门生成一些额外的代码,如果缺少这些代码,immix gc将无法正常工作。 所以虽然理论上我们可以将我们的immix gc用到其他项目中,这么做的效益很可能并不是很高-- 缺少编译器的支持,使用者将需要手动添加那些额外的代码。
immix gc的实现代码在这里。
pivot-lang immix gc
本文档将会描述pl使用的immix gc的一些实现细节与对外接口
Table of Contents
Overview
此gc是我们基于immix GC论文实现的, 大部分的实现细节都与论文一致,对于一些论文没提到的细节我们自行进行了实现,参考了很多别的GC项目。该GC是一个支持多线程使用的、 基于StackMap的,半精确mark-region 非并发(Concurrency) 并行(Parallelism) gc。
gc中并发和并行是两个不同的术语,并发gc指的是能够在应用不暂停的基础上进行回收的gc, 而并行gc指的是gc在回收的时候能够使用多个线程同时进行工作。一个gc可以既是并行的也是并发的, 我们的immix gc目前只具备并行能力
这里有一些创建该gc过程中我们主要参考的资料,列表如下:
- immix gc论文
- playxe 的 immixcons(immix gc的一个rust实现,回收存在bug)-- 很多底层内存相关代码是参考该gc完成的,还有在函数头中加入自定义遍历函数的做法
- 给scala-native使用的一个immix gc的C实现
- 康奈尔大学CS6120课程关于immix gc的博客,可以帮助快速理解论文的基本思路
General Description
本gc是为pl 定制的,虽然理论上能被其他项目使用,但是对外部项目的支持 并不是主要目标
pl的组件包含一个全局的GlobalAllocator,然后每个mutator线程会包含一个独属于该线程的Collector,每个Collector中包含一个
ThreadLocalAllocator。在线程使用gc相关功能的时候,该线程对应的Collector会自动被创建,直到线程结束或者
用户手动调用销毁api。
mutator
mutator指使用gc的用户程序,在有些文档里也被指代为gc的client
block
block是immix中全局分配器分配的基础单位,每个block的大小为32KB
line
line是block中的基本单位,每个line长度为128B,每个block中包含256个line
Global Allocator
全局分配器,简称GA,分配内存以block为单位
Thread Local Allocator
线程本地分配器,简称TLA,分配内存以line为单位,在自身的block中分配,如果没有可用的block,会向全局分配器申请
Collector
线程本地的回收器,在每次gc开始的时候会运行标记和驱逐算法,然后通知Thread Local Allocator进行清扫
Evacuation
驱逐算法,是一种反碎片化机制
下方是使用immix gc的应用程序的工作流程图:
graph LR;
subgraph Program
style Collector1 fill:#b4b2e6
style Collector2 fill:#b4b2e6
direction TB
subgraph Immix GC
direction TB
GA
Collector1
Collector2
end
GA[Global Allocator]--give blocks-->TLA1;
TLA1-.return free blocks.->GA;
subgraph Collector1
direction TB
TLA1[Thread Local Alloctor]
Marker1[Marker]
end
GA--give blocks-->TLA2;
TLA2-.return free blocks.->GA;
subgraph Collector2
direction TB
TLA2[Thread Local Alloctor]
Marker2[Marker]
end
subgraph Mutator
direction TB
Thread1
Thread2
end
TLA1--lines-->Thread1
TLA2--lines-->Thread2
Marker1-.Mark, evacuate.->TLA1
Marker2-.Mark, evacuate.->TLA2
end
Immix GC由于分配以line为单位,在内存利用率上稍有不足,但是其算法保证了极其优秀的内存局部性,配合TLA、GA的设计也大大 减少了线程间的竞争。
Allocation
Global Allocator
GA是全局的,一个应用程序中只会有一个,负责分配block。在GA被初始化的时候,会向操作系统申请一大
块连续的内存,然后将其切分为block,每个block的大小为32KB。GA有一个current指针,指向
目前GA分配到的位置。当GA需要分配新block的时候,GA会返回当前current指针指向的内存空间,
并且将current指针向后移动一个block的距离。
GA同时维护一个free动态数组,用于存储已经被回收的block,当GA需要分配新block的时候,会先从free数组中
尝试取出一个block,如果free数组为空,才会分配新的block。
Thread Local Allocator
TLA是线程本地的,每个线程都会有一个TLA,负责分配line,和进行sweep回收。
- 小对象:小于line size的对象
- 中对象:大于line size,小于block size/4(8KB)的对象
- 大对象:大于block size/4的对象
- hole:block中一个未被使用的连续空间称之为hole
在每次回收的时候,TLA会将所有完全空闲的block回收给GA,所有部分空闲的block会被加入到recycle数组中,在之后的分配里被重复利用。
所有完全被占用的block会被加入到unavailable数组中,不会被重复利用。
TLA的小对象分配策略如下:
graph TD;
A[分配内存]-->B{有recycle block?}
B--是-->C[从recycle block中分配line]
B--否-->D{申请新block}
D--成功-->E[新block加入recycle block]
D--失败-->I[panic]
E-->C
C-->F{block用完?}
F--是-->G[移入unavailable block]
F--否-->H[返回分配空间的指针]
G-->H
中对象存在一个问题,就是如果他采用小对象的分配策略,在recycle block中分配line,那么分配过程中可能跳过 很多的小hole,而TLA的分配器在recycle block中分配的时候是不回头的,这样可能会导致:
- 内存碎片增加
- 分配时间变长
因此,中对象分配的时候只会找recycle block中的第一个hole,如果这个hole装不下它,TLA会直接申请新的block来分配该对象, 并且将这个block加入到recycle block中。
大对象分配不使用mark region算法,它使用特殊的bigobject allocator来分配,是传统的mark free算法。
因为程序中小对象的数量远远大于中对象和大对象,所以TLA的分配器会优先优化小对象分配,以增加性能
Mark
Mark阶段的主要工作是标记所有被使用的line和block,以便在后续的sweep阶段进行回收。我们的mark算法是__精确__的, 这点对evacuation算法的实现至关重要。
精确GC有两个要求:
- root的精确定位
- 对象的精确遍历
我们的精确root定位是基于__Stack Map__的,这部分细节过于复杂,将在单独的文档中介绍。
对象的精确遍历是通过编译器支持实现的,plimmix将所有heap对象分类为以下4种:
- Atomic Object:原子对象,不包含指针的对象,如整数、浮点数、字符串等
- Pointer Object:指针对象,该对象本身是一个指针
- Complex Object:复杂对象,该对象可能包含指针
- Trait Object:Trait对象,该对象包含一个指针,在他的offset为8的位置,这个类型是专门配合pivot lang的trait设计的,是个特殊优化
对于Atomic Object,我们不需要遍历,因为他们不包含指针。
对于Pointer Object,我们只需要遍历他们的指针即可。
对于Complex Object,编译器需要在对象开始位置增加一个vtable字段,该字段的值指向该类型的遍历函数。此遍历函数由编译器生成,
其签名为:
pub type VisitFunc = unsafe fn(&Collector, *mut u8);
// vtable的签名,第一个函数是mark_ptr,第二个函数是mark_complex,第三个函数是mark_trait
pub type VtableFunc = fn(*mut u8, &Collector, VisitFunc, VisitFunc, VisitFunc);在标记的时候,我们会调用对象的vtable对他进行遍历
对于Trait Object,我们需要遍历他指向实际值的指针
下方是一个immix heap的示意图,其中*表示该对象会在mark阶段中被标记
graph LR;
subgraph Stack
Root1
Root2
Root3
Root4
end
subgraph HO[Heap]
AtomicObject1[AtomicObject1*]
AtomicObject2[AtomicObject2*]
AtomicObject3
PointerObject1[PointerObject1*]
PointerObject2[PointerObject2*]
ComplexObject1
end
subgraph ComplexObject1[ComplexObject1*]
VT1[VTable]
PF1[PointerField]
AF1[AtomicField]
ComplexField
end
subgraph ComplexField
VT2[VTable]
AF2[AtomicField]
PF2[PointerField]
end
PF1 --> PointerObject1
PF2 --> AtomicObject2
PointerObject1 --> AtomicObject1
PointerObject2 --> ComplexObject1
Root1 --> PointerObject1
Root2 --> PointerObject2
Root3 --> PointerObject1
对于ComplexObject1,他的vtable函数逻辑如下:
fn vtable_complex_obj1(&self, mark_ptr: VisitFunc, mark_complex: VisitFunc, mark_trait: VisitFunc){
mark_ptr(self.PointerField)
mark_complex(self.ComplexField)
}而对于ComplexField,他的vtable函数逻辑如下:
fn vtable_complex_field(&self, mark_ptr: VisitFunc, mark_complex: VisitFunc, mark_trait: VisitFunc){
mark_ptr(self.PointerField)
}实际上,mark_complex和mark_trait逻辑都十分简单:mark_complex只是调用对象的vtable函数,而
mark_trait只是对实际指针调用mark_ptr,真正的标记和驱逐逻辑都在mark_ptr中实现。
标记过程开始的时候,gc会load所有root指向的值,对他们调用mark_ptr,如果该值为gc堆中的对象,
则会将该对象标记,并且再次load它指向的对象,若该对象非AtomicObject类型则加入到mark queue中。
在mark queue中的对象,会被逐个取出,根据他们的类型对他们调用mark_ptr、mark_complex或者mark_trait,直到
mark queue为空,则标记过程结束。
尽管这的确可以看作是一个递归的过程,但是此过程一定不能使用递归的方式实现,因为递归的方式在复杂程序中可能会导致栈溢出。
Sweep
Sweep阶段的主要工作是:
- 回收所有未被标记的block
- 修正所有line的header
- 计算evacuation需要的一些信息
回收block
回收block的过程非常简单,我们只需要遍历所有的block,如果block的header中的mark字段为false,则将该block回收,统一返回给GA
修正line header
如果一个block被mark了,那么需要对block中的所有lineheader根据line是否被标记 进行修正。
计算evacuation信息
计算一个mark数组,该数组中下标为idx的元素值表示hole数量为idx的所有block的marked line的数量
Evacuation
每次回收开始之前,我们会先判断是否需要进行反碎片化,目前的策略是只要recycle block>1就进行反碎片化。
如果决定了需要进行反碎片化,那么我们会构建一个available数组,该数组中下标为idx的元素值表示hole数量为idx的所有block的可用line的数量,
然后我们按照洞的数量从大到小遍历available和mark数组,会定义一个required值,该值在每次遍历的时候加上mark数组中的值,
减去available数组中的值,如果某次循环后required值小于0,那么当前循环对应的hole数量+1就是我们evacuate的阈值(threshold)。
在此之后根据threshole将所有洞数量大于等于threshole的block标记为待evacuate。
真正的evacuation过程是在mark阶段一起完成的,我们会在遍历到处于待evacuate的block中的对象时,为它分配一个新的地址,并且
将它原地址的值替换为一个指向新地址的指针(forward pointer),且将line header中的forward字段设置为true。之后如果再次遍历到
该对象,收集器会修正指向原地址的指针的值,这一过程我们称之为自愈。该过程如下图所示
graph TD;
subgraph BeforeEva
direction TB
EvaBlock
EmptyBlock
Pointer
end
subgraph EvaBlock
Line1
Line2
LineK[...]
LineN
end
subgraph Line1
Addr[addr: 0x1000]
Value[value: 0x4321]
Forward[forward: false]
end
subgraph EmptyBlock
EL1
ELK[...]
end
subgraph EL1[Line1]
AddrEL[addr: 0x2000]
ValueEL[value: 0x0000]
end
Pointer
Pointer-->Line1
subgraph AfterEva
direction TB
EvaBlock1
EmptyBlock1
Pointer1[Pointer]
end
subgraph EvaBlock1[EvaBlock]
Line11
Line21[Line2]
LineK1[...]
LineN1[LineN]
end
subgraph Line11[Line1]
Addr1[addr: 0x1000]
Value1[value: 0x2000]
Forward1[forward: true]
end
subgraph EmptyBlock1[EmptyBlock]
EL11
ELK1[...]
end
subgraph EL11[Line1]
AddrEL1[addr: 0x2000]
ValueEL1[value: 0x4321]
end
Pointer1-->EL11
BeforeEva-->AfterEva
每次驱逐是以分配的对象为单位,如果一个block被标记为待evacuate,那么在驱逐过程中,该block中的所有对象都一定会被驱逐。
请注意,一部分其他gc的驱逐算法中的自愈需要读写屏障的参与,immix不需要。这带来了较大的mutator性能提升。
驱逐算法的正确性建立在我们的root定位和对象遍历的正确性之上,如果root定位和对象遍历不精确, 建议禁用驱逐算法。这二者的不精确会导致驱逐算法修改的指针不能完全自愈。考虑下方场景:
struct Node {
next: *mut Node,
data: u32,
}
fn main() {
let mut root = Node {
next: null_mut(),
data: 0,
};
let stack_ptr = &mut root as * mut u8;
add_root(stack_ptr);
}
fn add_sub_ndoe(root: *mut Node) {
let mut node = Node {
next: null_mut(),
data: 0,
};
root.next = &mut node;
}
在这个例子中,我们只添加了一个root即main中的root变量,尽管add_sub_node中的node变量和root参数也是root,
但是不添加它们其实不会影响大部分gc在这个例子中的正确性。然而如果启用了驱逐算法,这个例子就很可能在运行时出错。
假如add_sub_node函数中触发了gc,且gc决定进行驱逐,将main函数中的root变量移动到了新的地址,那么在gc过程中
stackptr对应的指针指向的位置会自愈,更改为移动后的地址,但是add_sub_node函数中的root参数因为没被添加到root set中,
这导致gc无法在回收过程中对其进行修正,就会进一步导致root.next指向的地址不正确,从而导致程序出错。
在多线程情况下,是存在两个线程同时驱逐一个对象的可能的,在这种情况下一些同步操作必不可少,但是并不需要加锁。 我们通过一个cas操作来保证只有一个线程能够成功驱逐该对象。
性能
我们与bdwgc进行了很多比较,数据证明在大多数情况下,我们的分配算法略慢于bdwgc,与malloc速度相当,但是在回收的时候,我们的回收速度要快于bdwgc。 对于一些复杂的测试,在触发回收的策略相同的情况下,我们的单线程总执行时间略慢于bdwgc,但是在多线程情况下,我们的总执行时间明显快于bdwgc, 整体来说机器并行能力越强、测试时使用内存越多immix性能优势越大。
使用github action进行的基准测试结果可以在这里查看,由于github action使用的机器 只有两个核心,所以测试线程数量为2,在此结果中,可以看到immix整体性能略差于bdwgc,但是差距小于单线程情况。
你可以从这里下载测试代码,在你的机器上运行并进行比较。这里我提供一组笔者机器上的测试数据截图
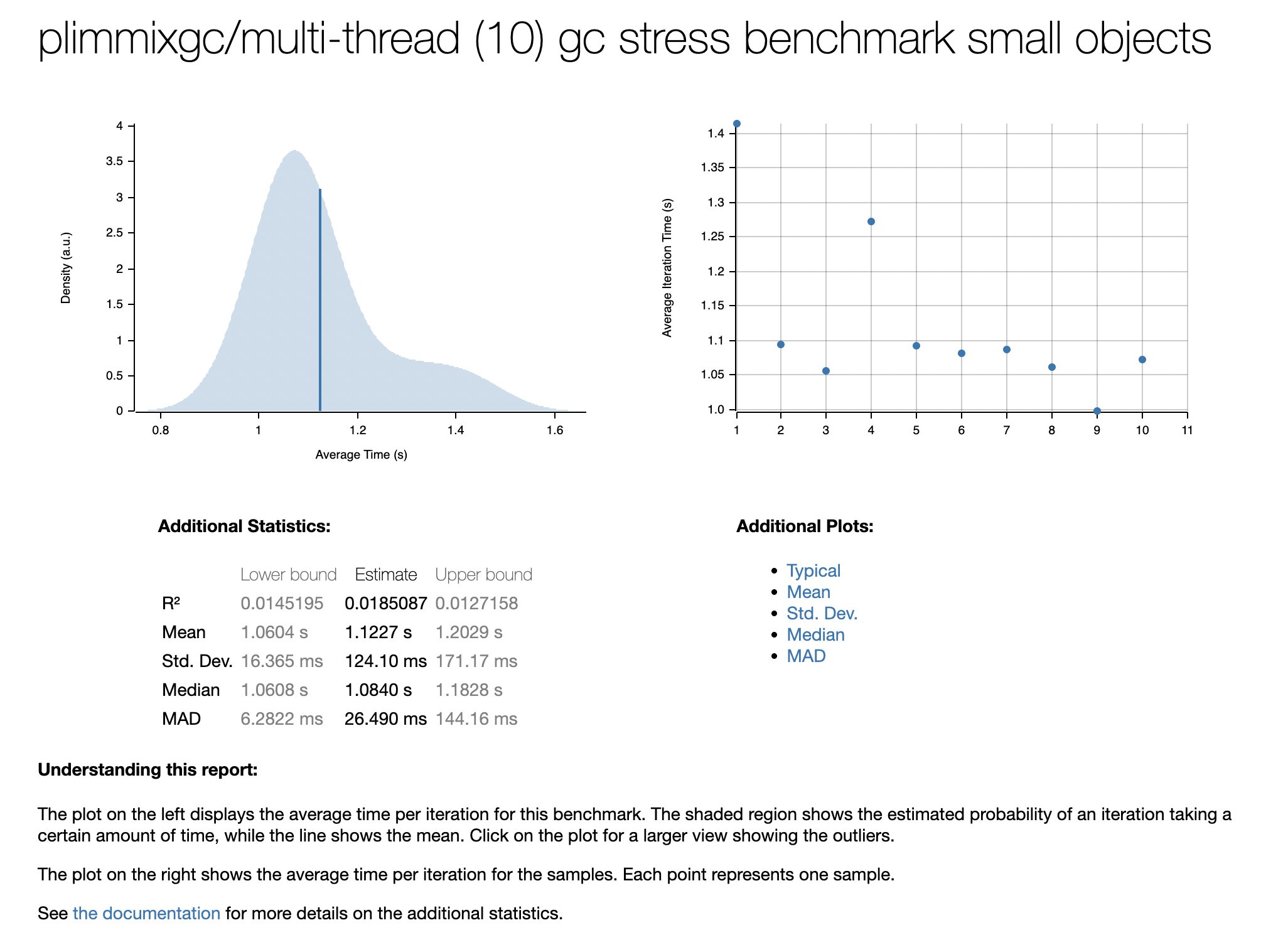
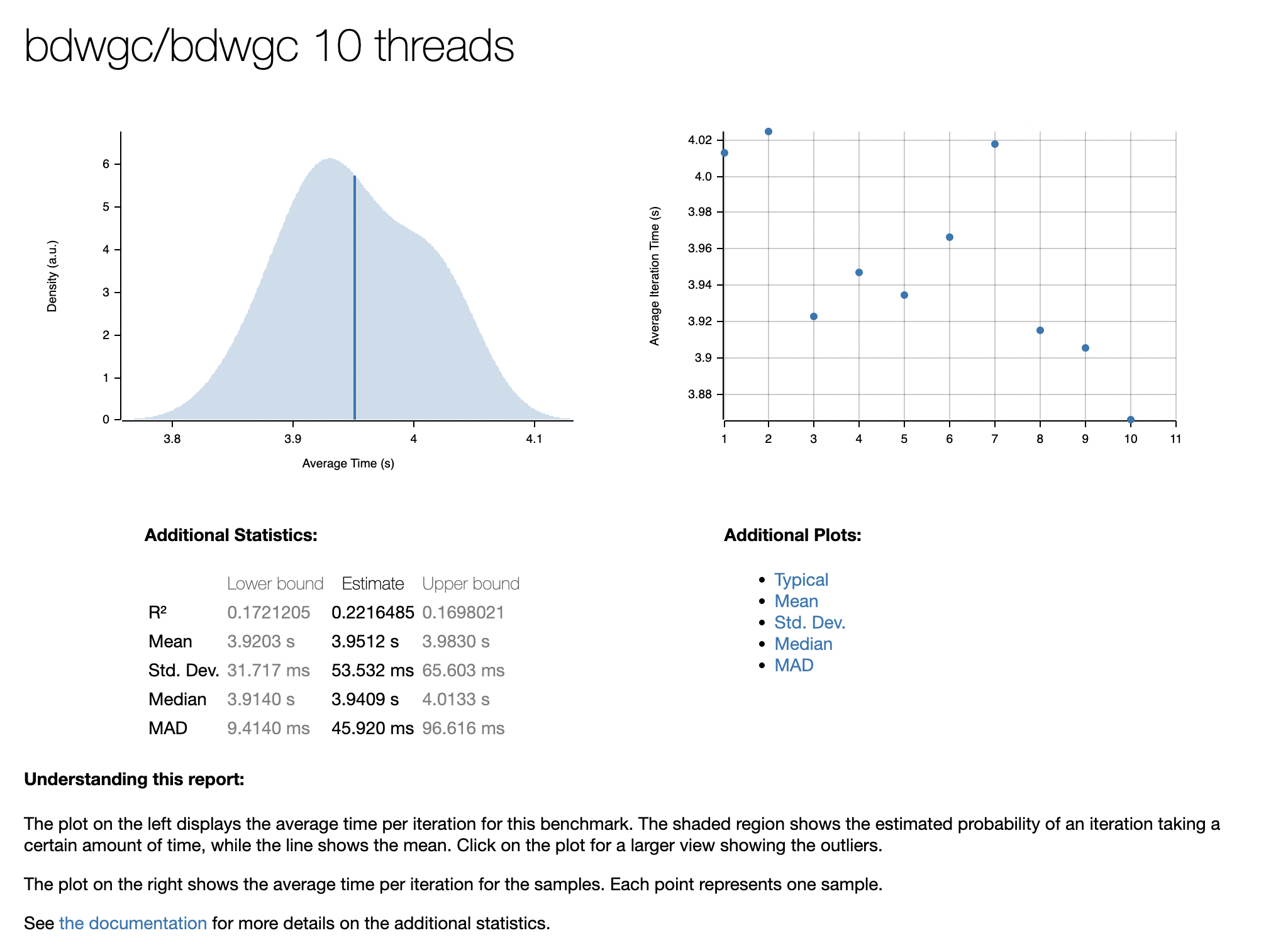
测试环境为MacBook Pro (16-inch, 2021) Apple M1 Pro 16 GB,可以看出immix在此环境中已经具有近4倍的性能优势。
immix作为天生并发的gc,并发情况下几乎能完全避免锁竞争的出现,因此在多线程情况下的性能优势是非常明显的。并且其分配算法很好的维护了空间局部性,理论上 能带来更好的mutator性能。
在线程卡顿的时候
线程进入卡顿状态(Sleep,lock etc.)的时候,需要使用thread_stuck_start通知GC,使GC可以启动一个保姆线程替代卡顿线程的工作。
Stak Map
Introduction
stackmap是一种用于实现精确gc的机制,简单来说它会在编译期间根据编译器提供的信息在编译后的目标文件 中插入栈变量的位置信息,这样在运行时gc扫描栈时就可以根据这些信息来确定栈上的变量的位置,从而完成精确回收。
stackmap方式的精确回收相比shadow stack的方式有以下优点:
- 无需维护gcroot链表,减少了开销
- 避免了运行时调用维护gcroot链表的函数形成的开销
但是同时它也有以下缺点:
- 跨平台存在劣势,各个平台的栈结构和可执行文件结构都有差异,stackmap过于底层,跨平台很复杂
- stackmap在回收的时候需要遍历函数调用栈,遍历栈的跨平台实现也很复杂,而且很多现有库都有bug
我们的stackmap功能基于llvm提供的一系列gc相关功能实现,llvm在这方面的文档十分混乱差劲, 甚至官网文档代码有一部分无法编译,还有很多地方严重过时与实际情况不符,因此全网都难找到基于llvm 实现stackmap功能的代码。本文档会尽量对这些部分进行说明。
细节实现
stackmap格式和读取方式
llvm提供了一系列的gc相关api,首先是gc策略,我们可以给每个函数指定一个gc策略,并且llvm内置了一些gc策略。
为了性能和方便考虑,我们的gc实现了自己的gc策略(plimmix),此策略通过一个自定义llvm插件实现。其代码在 immix/llvm 目录下 两个C文件一个定义了我们的GC策略,一个定义了我们的stackmap格式和生成方式。
我们的stackmap格式如下:
Header {
i64 : Stack Map Version (current version is 1)
i32 : function 数量
}
// 这里要对齐
Functions[NumFunctions] {
u64 : Function Address
i32 : Stack Size(单位是8字节)
i32 : 需要压栈的函数变量数量(不同平台不一样,大部分平台前6个参数会用寄存器传)
i32 : root数量
i32 : safe point数量
SafePoints[NumSafePoints] {
u64: 地址
}
Roots[NumRoots] {
i32: root的偏移(相对栈指针)
i32: root的类型
}
}
Global {
i32: global root数量
// 对齐
Roots[NumRoots] {
u64 : 地址
}
}
graph LR;
subgraph Front[编译器前端]
A[插入gcroot指令]
B[生成stackmap初始化代码]
A-->B
end
B-->C
subgraph Back[LLVM]
C[目标代码生成]
D[生成原始stackmap数据]
C-->D
end
D-->E
subgraph Plugin[Immix 插件]
E[生成stackmap]
F[写入目标代码数据段]
E-->F
end
safepoint是潜在的可以触发gc的点位,本来多用于进行多线程回收的同步:大部分gc 回收算法在回收时(全部或一部分时间)是不允许mutator运行的,这个时候需要暂停所有mutator 线程(stop the world),等回收完成后再恢复。使用safepoint机制的gc,在mutator线程运行到safepoint时会对 一个特殊flag进行检查,以判断自己是否需要暂停进行gc。在我们的immix gc中, safepoint通常由其中一个工作线程在自己的safepoint发起,别的线程到达自己的下一个safepoint是会随即暂停,等到所有线程 都暂停的时候再进行回收。我们的safepoint目前是在所有malloc点位,不过我们的llvm插件目前会将所有函数调用点位都当作 safepoint处理。
safepoint对于stackmap至关重要,因为在回收时gc就是通过在stackmap中查询当前暂停对应的safepoint地址来获取当前栈中的root集的。在暂停的时候safepoint地址在当前栈帧的ip寄存器中。
由于gc回收需要等待所有线程到达safepoint,所以如果一个线程长期不到达safepoint,别的线程在回收的时候就可能会一直等待。因此
immix提供一些工具函数。thread_stuck_start和thread_stuck_end,用于标记线程在执行某些长时间“卡住”的任务,在此期间
该线程需要保证不会使用gc分配新的内存,否则会panic。在线程被标记为stuck的阶段触发的gc会跳过同步该线程。no_gc_thread
可以告知gc目前正在执行的线程不需要gc功能,该线程不会分配对应的ThreadLocalAllocator。
我们的llvm插件会将stackmap信息生成到每个目标文件的数据段中,应用程序可以使用weak link的方式用对应的全局变量获取到这个数据标签对应的地址,然后就可以通过这个地址来获取到stackmap信息了。对应数据区域标签的命名规则是:_GC_MAP_$source_file_name,其中$source_file_name是对应llvm module中记录的的源文件名。
stackmap有多种读取方式,下方是我们使用的方式:
immix gc提供了gc_init函数,该函数接受一个stackmap指针,会加载该stackmap。我们的编译器
会在编译的时候为每个模块生成一个初始化stackmap的函数,该函数以一定的规则命名,之后
在生成主模块的的时候会自动在main函数开始处对这些初始化函数进行调用。
这部分代码理论上可以通过llvm插件自动完成,这部分以后应该会进行实现。实现此功能之后,我们的immix gc将会成为可以方便的给任何基于llvm的语言接入的gc。
gc_init函数主要会读取stackmap中的数据并且进行遍历,之后生成一个哈希表,用于快速的查找对应的safepoint地址。这个哈希表的key是safepoint地址,value是safepoint所在
函数的所有gcroot信息。
基于stackmap的精确root定位实现
为了遍历函数调用栈,在老版本中我们使用backtrace.rs包,该包封装了一些平台相关的函数调用栈遍历的实现。
在新版本中,由于libbacktrace中使用了全居锁,性能不好,我们决定手动进行栈遍历。为了完成这一点,我们需要
在mutator调用可能触发GC的runtime函数时,传入当前的sp寄存器值,之后利用StackMap中记录的各个函数栈的大小来一步一步往上爬取。
参考资料
Evacuation in practice
驱逐算法在实践中很容易造成内存安全问题,本文将会探讨常见的一些内存安全情况, 列举其他gc的一些解决方案以及他们的问题,以及PL所采取的解决方案。
这个页面只包含驱逐算法的一部分信息,如果你对gc感兴趣,可以查看immix页面。
1. 前言--驱逐算法的简单介绍
在垃圾回收算法中,经常会面临内存碎片化的问题,这种问题会导致内存的利用率降低,空间局部性降低,从而导致程序的性能下降。 解决这个问题通常有两种思路:驱逐与压缩。
简单来说,驱逐算法是将内存中的对象移动到另一块空的内存区域,然后回收原本的内存区域。而压缩算法则是将内存中的对象重新 排列,使得内存中的对象最终连续排列。我们的Immix GC采用的是驱逐算法。
graph TD;
subgraph 驱逐之前
A
B
end
subgraph A[内存区域1]
Obj1
Empty1
Obj2
Empty2
end
subgraph B[内存区域2]
Empty3
Empty4
end
Obj1-.驱逐.->Empty3
Obj2-.驱逐.->Empty4
subgraph 驱逐之后
C
D
end
subgraph C[内存区域1]
Empty5
G[Empty1]
Empty6
H[Empty2]
end
subgraph D[内存区域2]
E[Obj1]
F[Obj2]
end
驱逐之前-->驱逐之后
2. 驱逐算法的问题
驱逐算法虽然能够解决内存碎片化的问题,但是也存在一些缺点:
- 性能损耗:驱逐算法需要将内存中的对象移动到另一块内存区域,这个过程会消耗一定的时间。
- 内存安全:驱逐算法在移动对象的过程中,会导致原对象的引用失效,从而导致内存安全问题。
在immix中,驱逐和标记过程一起完成,总体性能损耗是很小的。而对于第二点,业界的主流做法是采用forward pointer。
即:在驱逐一个对象的时候,往这个对象原本的内存空间中写入一个指向新内存空间的指针,方便之后利用这个信息对 原对象的引用进行修正。
graph LR;
subgraph 驱逐之前
S[stack_pointer]-->A[Space1]
A-.驱逐.->B1[Space2]
end
subgraph 驱逐之后
S1[stack_pointer]-->B[Space1]
B-->A1[Space2]
end
驱逐之前-->驱逐之后
而修正引用的方法有多种,其中一种是使用读写屏障,这种方法的缺点是需要在每次读写的时候都要进行判断,会导致mutator严重的性能损耗。
graph LR;
subgraph load指针
S1[stack_pointer]--load-->B[Space1]
B-.发现B中是forward pointer,继续load.->A1[Space2]
end
subgraph 修正
S2[stack_pointer]-->A2[Space2]
B2[Space1]-->A2[Space2]
end
load指针-->修正
这种做法称为自愈,他的一大优势是在一些情况下可以避免gc暂停。
我们的做法是在gc暂停的时候,在第一次驱逐的时候安装forward pointer,之后的标记过程中遇到forward pointer就进行修正,这样避免了读写屏障。同时immix的修正与mark一起进行,不需要多次遍历,相对来说效率很高。
但是这种做法需要编译器良好的配合来避免内存安全问题,稍有不慎就会segfault/bus error。
3. 内存安全注意事项与解决方案
几乎所有的内存安全问题都是由于引用没有正确更新。也就是说在gc回收驱逐了一部分内存之后,一部分引用还指向了原本的内存空间。
graph LR;
subgraph 驱逐之前
S[stack_pointer1]-->A[Space1]
S2[stack_pointer2]-->A[Space1]
A-.驱逐.->B1[Space2]
end
subgraph 驱逐并且修正之后
S1[stack_pointer1]-->A1[Space2]
S3[stack_pointer2]-->B2[Space1]
end
驱逐之前-->驱逐并且修正之后
上图中,stack_pointer2指向的引用没有被修正,之后访问它指向的内存空间就可能会出错。
为了避免该问题,我们需要在编译时提供信息给gc,让gc能够知道所有指向堆变量的栈指针。这样gc就能够在驱逐的时候将这些指针进行修正。
具体来说,我们需要进行两项工作:
- 所有llvm ir中 独立存在的 堆变量都必须有个对应的stack alloca,并且该alloca要被注册为gcroot
- 每次获取llvm值的时候,如果该变量为 独立存在的 堆变量,必须从它对应的stack alloca中load出来
所谓 独立存在的堆变量 指的是llvm ir中作为左值存在,并且在下一次GC_malloc之后可能被使用的堆变量。为了保险起见,
目前在我们的代码中,所有GC_malloc的返回值,所有bitcast的结果,所有load的结果,以及所有gep结果都被认为是 独立存在的堆变量 。
其中第二点已经在get_llvm_value中统一进行了处理,而第一点则需要在开发者在编写代码的时候自己进行注意。为了方便,llvmbuilder中增加了create_root_for函数
帮助开发者注册stackroot。
planglib
planglib目录下的每一个文件夹都是一个系统模块,在编译的时候会自动被加入依赖中,不需要在配置文件中特殊配置。
planglib如何在编译期间被找到
plc编译器在编译时会试图寻找KAGARI_LIB_ROOT环境变量,并且将该变量视为planglib的根目录
不设置或错误设置
KAGARI_LIB_ROOT环境变量可能导致无法进行编译或者代码分析
如果你是plang开发者,你可以手动在~/.bashrc或者~/.bash_profile中加入以下代码:
export KAGARI_LIB_ROOT=<pivot-lang project path>/planglib
编译原理
这个章节会介绍一些编译原理的基础知识,方便新手入门
递归下降分析法
这章介绍我们编译的第一个步骤:递归下降分析。
递归下降法是一种用于构造LL语法分析器的技巧。在这种方法中,对于语法的每个非终止符号,我们都有一个函数来处理。
下面是一个基本的递归下降解析器的实现,我们将用它进行一个简单的算术表达式解析:
/// expr = add | sub | num /// add = num '+' expr /// sub = num '-' expr #[derive(Debug, Eq, PartialEq, Clone)] pub enum Expr { Add(Box<Expr>, Box<Expr>), Sub(Box<Expr>, Box<Expr>), Num(i64), } #[derive(Debug, Clone)] pub enum Token { Plus, Minus, Num(i64), End, Err, } #[derive(Debug)] pub struct ParseError; fn next_token(input: &str) -> Result<(Token, &str), ParseError> { let input = input.trim_start(); let (token, rest) = match input.chars().next() { Some('+') => (Token::Plus, &input[1..]), Some('-') => (Token::Minus, &input[1..]), Some(ch) if ch.is_digit(10) => { let digits: String = input.chars().take_while(|ch| ch.is_digit(10)).collect(); let len = digits.len(); (Token::Num(digits.parse().unwrap()), &input[len..]) } Some(_) => return Err(ParseError), None => (Token::End, ""), }; Ok((token, rest)) } fn add(input: &str) -> Result<(Expr, &str), ParseError> { let (left, rest) = num(input)?; let (token, rest) = next_token(rest)?; if let Token::Plus = token { let (right, rest) = expr(rest)?; Ok((Expr::Add(Box::new(left), Box::new(right)), rest)) } else { Err(ParseError) } } fn sub(input: &str) -> Result<(Expr, &str), ParseError> { let (left, rest) = num(input)?; let (token, rest) = next_token(rest)?; if let Token::Minus = token { let (right, rest) = expr(rest)?; Ok((Expr::Sub(Box::new(left), Box::new(right)), rest)) } else { Err(ParseError) } } /// expr = add | sub | num fn expr(input: &str) -> Result<(Expr, &str), ParseError> { add(input).or_else(|_| sub(input)).or_else(|_| num(input)) } fn num(input: &str) -> Result<(Expr, &str), ParseError> { let (token, rest) = next_token(input)?; if let Token::Num(val) = token { Ok((Expr::Num(val), rest)) } else { Err(ParseError) } } fn main() { let input = "1 + 2 - 3"; let (expr, rest) = expr(input).unwrap(); assert_eq!(rest, ""); assert_eq!( expr, Expr::Add( Box::new(Expr::Num(1)), Box::new(Expr::Sub(Box::new(Expr::Num(2)), Box::new(Expr::Num(3)))) ) ); }
针对这段代码,我们有四条语法规则,每条规则对应一个分析函数。这些函数的返回值是一个enum,在正确的情况下返回的是生成的语法树 以及剩余的字符串。如果解析失败,返回一个错误。
仔细观察可以看出,递归下降法和语法规则是直观对应的,例如规则expr = add | sub | num,expr函数的逻辑就是
顺序调用add、sub、num函数,如果其中一个成功,就立刻返回成功的结果,否则返回错误。
所以只要能明确写出对应的语法,将语法转换为递归下降分析的代码就是一件非常简单的事情了。你可以试试将上面的代码修改一下,增加对乘法和除法的支持, 并且思考递归下降中如何处理优先级的问题?
为Pivot Lang贡献代码
非常感谢您愿意对本项目提供帮助!
下方是对您为 pivot-lang 贡献代码的一些帮助
如果您刚开始了解pivot-lang项目,可以加入我们的社区 qq 群 向我们提问.
因为本项目还处于早期阶段: 本页面的指导很可能会在未来有更改,欢迎帮助我们改进此页面!
基础
开发文档
我们的基础环境配置教程在 dev-prepare 中,开发前请务必阅读。
开源协议
本项目使用 MIT 协议。对本项目贡献代码即表示您同意您的更改遵守该协议。
您能做的事情
Issues
我们有很多的已有的issue,在添加新功能的时候我们也会添加相关的issue。如果您发现我们的bug或者有什么需求,欢迎新建 issues 来告诉我们。您也可以看一些 open 的issue并且参与讨论或者贡献代码帮助修复它。
Code
非常欢迎帮助我们实现新功能。我们的新功能实现分为几个阶段:
- 提出,讨论需求的合理性和必要性
- 讨论实现方案
- 实现
- reveiew
- 合并
一些简单的需求可以跳过第二个阶段,所有超过第一个阶段的需求都会被放在我们的project中。如果您想帮助实现 已有需求,请去此页面寻找处于new或者ready状态的项目。如果您想实现一个新的需求,请先在issues中提出,最好加入 qq群 和我们一起讨论方案,在讨论决定通过后,我们会在project中添加一个新的对应项目。
Tests
强烈建议在提交修改的时候同时添加对应的测试,帮助我们将测试覆盖率保持在 85%, 帮助我们进一步完善测试也是相当欢迎的。
请在提交pr前确认自己的修改能通过所有的测试(通过运行 cargo test --all)
Benchmark
目前我们还没有基准测试,欢迎帮助我们添加基准测试。
文档
参见 文档 网站。对应源码在 book 目录中,欢迎帮助我们完善文档。
风格
Issue 风格
请在提出issue时提供至少三个小自然段的说明,包括:你想干什么,遇到了什么问题,如果复现这个问题等。
如果可能的话,希望您能提供:
- 如果是在使用的时候遇到的bug,最好有一小段代码或者一个指向 gist 的链接,其中包含能复现问题的代码。
- 完整的 backtrace, 如果是进程崩溃相关的问题。
- 一个示例项目,如果是编译相关的问题。
代码风格
rust代码风格通过使用 rustfmt 进行统一 请尽量减少代码重复率,增加可读性。
为了避免不同的rust小版本格式化的区别,请使用以下命令格式化: cargo +stable fmt
其他重要事项
Immix GC对代码生成的影响
Pivot Lang使用的Immix GC是一个精确的、可重定位的垃圾回收器。重定位(evacuation)指 GC在触发的时候可能会移动堆中的对象,这主要是为了解决内存碎片化的问题。
GC的重定位正确性依赖于严谨准确的代码生成。
由于GC要保证堆对象在被移动之后,所有指向原对象位置的指针都被更新为指向新对象,所以GC需要 知道所有指向堆对象的指针。所以在Pivot中,一切堆对象的直接或间接的指针都会有个对应的栈 指针。同时,因为触发重定向的逻辑比较复杂,这种问题往往很难测试出来,具有很高的随机性, 所以目前的debug模式编译的GC在每次malloc都会触发GC,并且会强制每次回收都触发重定向,并且每一个堆里的对象都会被重定向。
Blogs
Some development blogs.
聊一聊pivot-lang
这是这个项目的第一篇博客,这篇博客里我准备讲一讲这个项目的意义还有它的发展方向,还有一些写的过程中的有趣的话题。
这个项目希望创造出一种好用的类rust的新编程语言,他要具有大部分先进的特性,并且避免掉rust太难学习的缺点。
目前已经完成的部分和rust非常的像,但是已经有一些功能上出现区别,比如模块化。模块化表面上和rust有点像,但是其实完全不一样,要说类似其实反而和go更类似一些,不过也有很大区别。
我们预计之后的一些高级功能,比如代数类型、模式匹配和一些别的特殊语法糖上,我们会和rust有巨大分歧,这方面还敬请期待。
History
项目大概是2022年9月中旬开始的,一开始的时候我们几乎完全手写了第一版lexer和parser。当时那一部分代码大部分是@RINNE-TAN写的,因为我那个时候还不会rust,只能对@RINNE-TAN的代码进行拙劣的模仿。我们初期争论比较大的点是是否该用lr分析法的工具,而不是ll分析手写递归下降。最后我们还是觉得ll可控性更好一些,选择了手写。但是就写了个开头,我们就发现这玩意写到后边可维护性会有很大问题,简直是依托__。
所以我们开始重新考虑一些自动或者半自动的工具,比如antlr、lalrpop之类的。这些工具有个很严重的问题,就是他们往往需要在特殊格式里编写一部分源代码,而写这部分代码的时候是没有代码提示的。这对于其他的语言应该好一些,但是这对于rust来说是相当致命的,尤其是在我们没有人是rust大佬的情况下。
这个时候伟大的@RINNE-TAN找到了nom,虽然这个东西上手有点不习惯,但是熟练之后被证明究极好用,于是我们果断重写了之前的lexer和parser的代码。我代码量大概就是这个时候开始反超@RINNE-TAN的,因为重构几乎都是我搞的。
之后我们十一之前加班加点,希望在10.1期间作出一个有一些基础功能的版本,这期间有很多人都参与了代码编写,不过总体来说这一阶段的工作是比较简单的。唯一一个相对难一点的功能是@CjiW做的函数相关的功能,函数至今也是我们代码生成中最复杂的模块之一。
十一之后我们加入了大量lsp相关的功能,还有debug支持。这两个都是之前我做的项目中比较少或者没有涉及过的,意外的是这两个功能的实现都比较顺利。
顺带一提,项目里很多奇怪的东西还有一些文件的命名多少沾点二次元,这都是托了@RINNE-TAN大爷的福。
再后来,我们的高级功能开始提上日程,@RINNE-TAN几乎实现了泛型功能的所有代码,这部分逻辑十分复杂,因为涉及到自动泛型推断和代码膨胀等技术,是目前编译器中最复杂的功能之一。谢谢你,@RINNE-TAN!
顺便提一句,@RINNE-TAN现在是单身,如果有人对找程序员男朋友感兴趣,请抓紧
Future
接下来一段时间的首要任务是完善泛型功能,让impl快能加泛型,接口也支持泛型。然后,就是代数类型和模式匹配,这些任务预计寒假能搞完。之后的高级功能就是闭包和协程支持,然后需要完善系统库,gc支持多线程。如果非常顺利的话,寒假结束前有机会完成到协程。
项目现在非常缺人,如果你对开发pl感兴趣,请联系我们。
代码分析和差量计算
在lsp的文档中我简单介绍了差量计算在lsp模块中起到的优化作用,这里我将会详细介绍一下这个过程,希望能帮没接触过差量计算的小伙伴了解为何差量计算对于lsp的计算任务来说如此重要,以及什么情况下适合使用差量计算。
纯函数
差量计算中的基础对象一般是纯函数,纯函数的定义是:对于给定的输入,总是会有相同的输出,而且不会有任何副作用。
请注意其中不会有任何副作用这一点,如果要建立一个正确工作差量计算模型,必须要保证这一点。
带有副作用的函数为什么会影响差量计算正确性?
试想以下场景:我有两个参与差量计算的基础函数A和B,A不是纯函数,它会修改全局变量a,每次运行他会把a加一。
那么在某次计算过程中,A的输入与上次相同,B有变化,这导致B被重新执行了,而A直接使用上次缓存的计算结果,跳过了这次计算。那么这会导致本次计算全局变量a没有被A修改。这导致一个很严重的问题:即使用差量计算之后相比使用之前,相同情况下计算的影响不一样。
假设上方例子中不使用差量计算,那么A会被重新执行一次,这样a相比差量计算情况就会被多加一,正确的差量计算模型不应该对系统状态有影响,所以如果要使用差量计算,应该保证所有参与计算的函数都是没有副作用的纯函数。
一些容易被忽略的副作用情况
尽管纯函数的定义比较简单,上方的例子也比较直观,但是实际生产中其实很多函数都是有副作用的,而且很多初学者可能并不能完全分析出这些函数 的副作用。这里特别说一个容易被忽略的副作用情况:
- 修改被差量计算框架缓存的函数输出结果
在你分析一个函数有没有副作用的时候应该记住:被缓存的纯函数输出也属于全局状态,和全局变量没有本质区别。所以修改这些被缓存值也是有副作用的。修改这些值很可能在无意中发生:比如函数A的输出中有个类型指针,它输出后作为输入传给了函数B,函数B修改了这个类型指针指向的值,这样虽然看起来没有进行和全局变量相关的操作,但是实际上这个类型指针指向的值就是被缓存的函数A的输出,这种行为修改了缓存状态,是有副作用的。
差量计算系统设计原则
有了上方纯函数相关的知识,我们可以总结出一个正确的差量计算系统需要遵循的两条原则:
- 差量计算系统中,一个函数的输出应该是只读的,应该避免在别的函数中修改对应值
- 差量计算函数不能修改任何全局状态
实战举例--lsp引用查找功能设计
lsp引用查找是一个绝大部分语言插件都有的功能,它被使用的也很多,大部分程序员同学应该每天都会用到很多次。这个功能底层实现是比较简单的,如果不考虑差量计算的话:
在符号表中所有能被引用的符号中多存一个
refs链表,每次该符号被使用,往链表中加入被使用的位置。最后在接收到find reference请求的时候,查找到对应的符号,返回refs链表即可。
但是这么设计在差量计算的时候会遇到问题:假设我们差量计算的最小单位是compile_file函数,它的意义是编译一个文件,那么这个函数输出的编译结果中就应该包含该文件中定义的所有的符号,自然也包括这些符号的refs信息。然而,很多符号是可以被跨文件使用的,比如全局变量,这些符号的refs信息是跨文件的,所以这些符号的refs信息可能会在对别的文件调用compile_file函数时被修改,这样就违反了差量计算系统的第原则:差量计算函数不能修改任何全局状态。
如果我们直接用这种设计来进行差量计算的话:
假设有文件
A和文件B,A中有全局变量a,B中使用了全局变量a,第一次编译是全量编译,生成了正确的refs信息。第二次编译的时候,用户只修改了B,所以A的编译被跳过,复用了上次结果。这时请注意:a的refs链表是包含上次编译产生的完整结果的,而不是只有A文件中的引用信息,这一切都是因为B在编译的时候可能改A的编译结果,往a的refs里加值。
所以我们需要重新设计这个功能,我们需要把refs信息从符号中移除,放到一个与编译文件绑定的refs表中,这个表可以是map[str]vec<Location>类型,他只记录当前文件中符号的引用信息。当lsp收到find reference请求的时候,先找到对应的符号,然后再遍历所有文件的编译输出,找到对应符号在各个refs表中的记录,并且汇总。这样就可以保证差量计算的正确性了。
总结
我不是很擅长写文章,不知道这篇表达的清不清楚,如果能帮助到你就再好不过了。文章篇幅限制,这篇博客里跳过了差量计算框架的使用细节。 如果你对这方面感兴趣,可以参考我们的源代码。
~~牛马都能看懂的~~GC原理介绍
本文不要求你有任何高深的底层知识,本文的书写宗旨是让一个牛马都能看懂GC的基本原理
故事
首先,想象你是一个大学生,和三个舍友一起住在一间宿舍里。你们四个人都有自己的床,自己的书桌,自己的衣柜,自己的书架,自己的电脑,自己的手机,自己的鞋柜,自己的鞋子,自己的衣服。。。
一切都很美好,直到你们发现你们的宿舍里的垃圾日益变多,整个宿舍变得更加脏乱,逐渐不适宜居住了。于是你们决定开始定期清理垃圾。
怎么定义一个物品是不是垃圾呢?你们想了一种方法:以每个人为原点出发,寻找所有你可能直接 使用的物品,然后再从这些物品出发,寻找所有这些物品可能会用到的其他物品,依此类推,直到所有直接或间接可能被使用的物品 都被找到,剩下的物品就是不会再被用到的物品,也就是垃圾。
位了清理垃圾,一开始你们选择值日制度,每天轮流值日,值日的人负责清理宿舍里的垃圾,清理完毕后,将垃圾扔到宿舍外的垃圾桶里。这样,宿舍里的垃圾就被清理干净了,宿舍也变得干净了。
但是后来你们发现这样做有一个问题,就是每天都要有人值日,而且值日的人要花费很多时间清理垃圾,而且有些人垃圾多 有些人垃圾少,垃圾少的人和垃圾多的人都要花费同样的时间清理垃圾,这样就不公平了。于是你们决定改进一下,改成 每个人都有自己的垃圾桶,所有人都可以随时清理自己的垃圾,这样就不用每天都有人值日了,而且每个人清理垃圾的时间 也可以岔开,对于大家都方便。
这套机制稳定的运行了一段时间,直到你们发现宿舍里有一个人特别的懒,他从来不清理自己的垃圾,他的 垃圾逐渐堆积,甚至有时候会散布到宿舍的其他地方,这样宿舍里的垃圾又开始变多了,宿舍又变得脏乱了。
这个时候宿舍里一个有洁癖的人就受不了了,他帮助懒人清理了他的垃圾,然而懒人发现之后 非但没有感谢,反而指责他丢掉了他还要继续使用的东西。两人爆发了严重的争吵。
最后为了避免这个问题,宿舍经过讨论找到了一个完美的解决方案:每个人在不方便清理自己垃圾的时候,都需要 请一个保姆来代替自己清理垃圾,在自己方便的时候再把保姆送走。
最后,你们宿舍终于变成了一个高效、少吵架的宿舍。
问题
这个故事里的意象都象征着什么?你看懂了吗?
Performance Optimization
Introduction
Performance matters. Although speed may not be the most important factor in some languages, it is a universal truth that nearly all languages can benefit from higher performance.
Higher performance can lead to better user experience, lower server costs, and more efficient use of resources. It can also give your application a competitive edge.
However, achieving high performance is not easy. It requires a deep understanding of the language, the runtime, and the hardware. It also requires a lot of time and effort. In this blog post, we will discuss some of the techniques that can be used to optimize the performance of a programming language and how we applied them to Pivot Lang.
Main Factors Affecting Performance
1. LLVM Optimization
LLVM is a powerful compiler infrastructure that can be used to generate highly optimized machine code. However, it can not do much if the ir code generated by the frontend is not following the best practices. It is not enough to just generate correct code, you need to add various metadata to help LLVM optimize the code. You can find more information about this in the LLVM documentation.
2. Garbage Collection
If you are using a garbage collector, it is important to make sure that it integrates well with the rest of the system. Even the best garbage collector can cause performance issues if it is not used correctly.
Garbage collectors have two basic types: conservative and precise. There's not much we can do while using third party fully conservative garbage collectors (like bdwgc), but with custom precise garbage collectors, we can make a large difference by changing the mechanism of stack scanning, adjusting collect frequency etc.
Stack Scanning
There are many different ways to scan the stack, if you are not using llvm's gc api, you can scan the stack
conservatively, very much like bdwgc does, it's fast enough in most cases. Otherwise, you can choose between
llvm's gc.root and gc.statepoint to perform precise stack scanning.
Even with the same llvm scanning method, you can still make a difference by changing the way you
crawl the stack, for example, you can use libunwind to walk the whole stack, or you can use llvm's
inline assembly to get the stack pointer and walk the stack manually by the help of stackmap.
Those mechanisms are discussed in detail in the LLVM and GC post.
Collect Frequency
The frequency of garbage collection can have a big impact on performance. Different GC algorithms may have different optimal collect frequencies, and it may not make sense at all for some concurrent GCs. Generally speaking, GC should take less than 10% of the total time, otherwise, you should consider optimizing it.
Allocation
The way you allocate memory can also have a big impact on performance.
Memory allocation is a well-known hot path in many programs,
especially in programs that allocate all objects on the heap.
You should make sure your allocator is fast and efficient.
A good allocator should allocate memory at least as fast as libc's malloc
in single-threaded environments.
Although a good allocator can improve performance, it won't help much if you are allocating memory too frequently. You should try to minimize the number of heap allocations in your program. This can be done either by dead code elimination or by replacing some heap allocations with stack allocations.
As mentioned in the blog,
you can add metadata allockind("alloc") to your custom allocate function
to allow llvm to optimize away some allocations.
On the other hand, you can also use alloca to replace some heap allocations,
the well-known language golang uses a simmilar mechanism to reduce the number of heap allocations.
However there's no built-in pass in llvm to do this, you have to write your own pass.
Fortunately, llvm does provide an analysis pass named CaptureTracking which can help you
to determine whether a heap pointer can be safely replaced with alloca.
Please note that replacing heap allocations with stack allocations can be dangerous,
especially if you are using a precise relocating garbage collector. Things can get
complicated in this case, and you may need to add some extra metadata to help the
pass to determine whether a not captured pointer can be safely replaced with alloca.
Take Pivot Lang as an example, we originally used a precise relocating garbage collector,
and our GC used a visitor function on the object header to precisely mark complex objects like
structs, arrays, etc. Imagine if we replaced a heap allocation of a complex object with alloca,
then the visitor function is also on the stack, and we in fact cannot use it to mark the object,
as we cannot distinguish the visitor function from other stack data. This is not a problem
if we conservatively scan the stack if all the heap pointers in the stack are ordinary --
which means our GC can know the exact way to scan their content based only on the pointer itself.
In Pivot Lang, array types are not ordinary, so we added extra metadata to help the pass to
disambiguate the array type from others. So at last, our GC becomes a hybrid one, which
scans the stack conservatively and scans the heap precisely. We are undertaking this approach to achieve a substantial reduction in the number of heap allocations, even if it means slightly slowing down the speed of stack scanning.